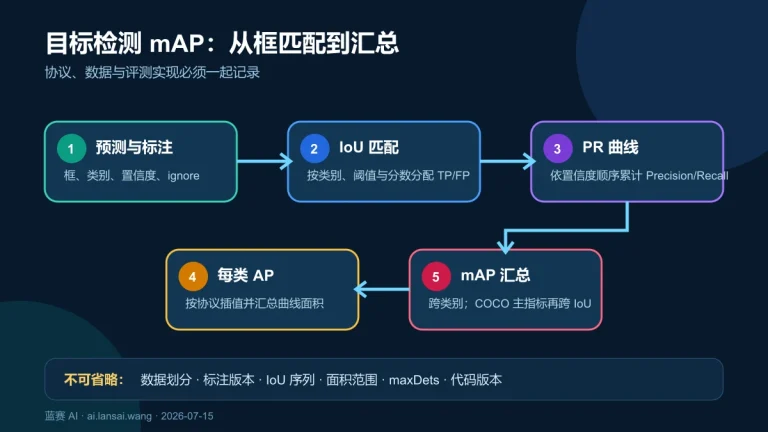
监督学习:定义
监督学习是机器学习的一种核心范式,其核心思想是让算法从一组包含“问题”(输入特征)和“标准答案”(输出标签)的标注数据中学习规律,从而构建一个模型,用于对新的、未见过的数据做出准确的预测或分类。
监督学习的工作原理
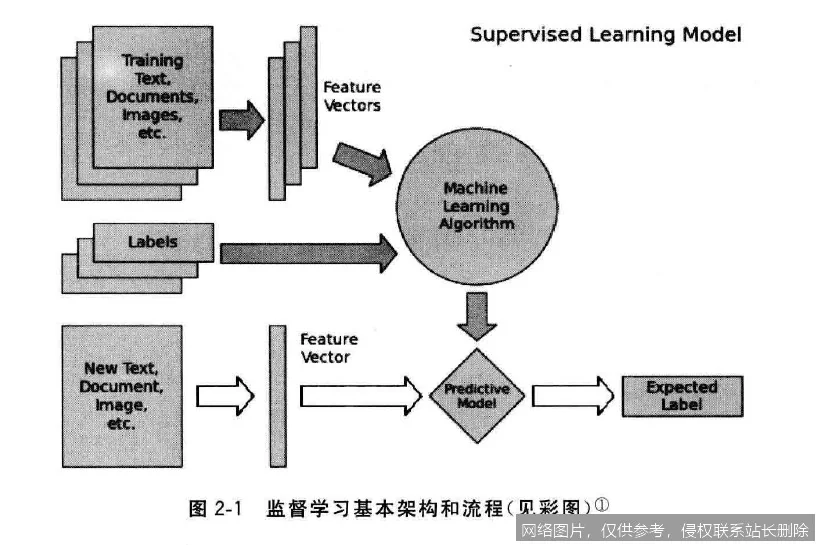
监督学习的过程可以类比于一位学生备考。老师(数据提供者)为学生(算法)提供一本带有详细答案的习题集(标注数据集)。学生通过反复练习这些题目,分析题目(输入特征)与正确答案(输出标签)之间的对应关系,总结出解题的规律和模式(训练模型)。最终,当学生面对一份全新的、没有答案的试卷(新数据)时,他能够运用总结出的规律,独立解答出题目(做出预测)。
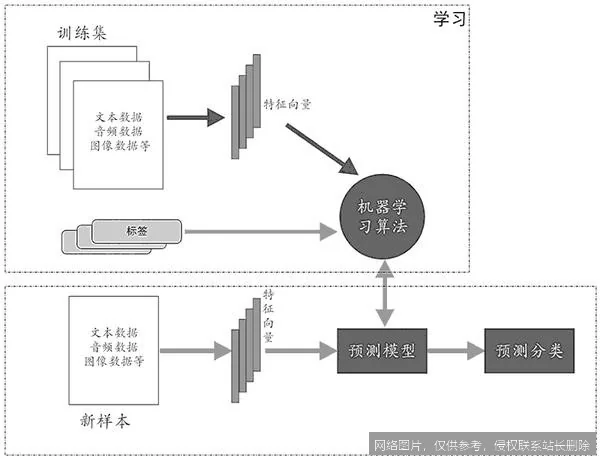
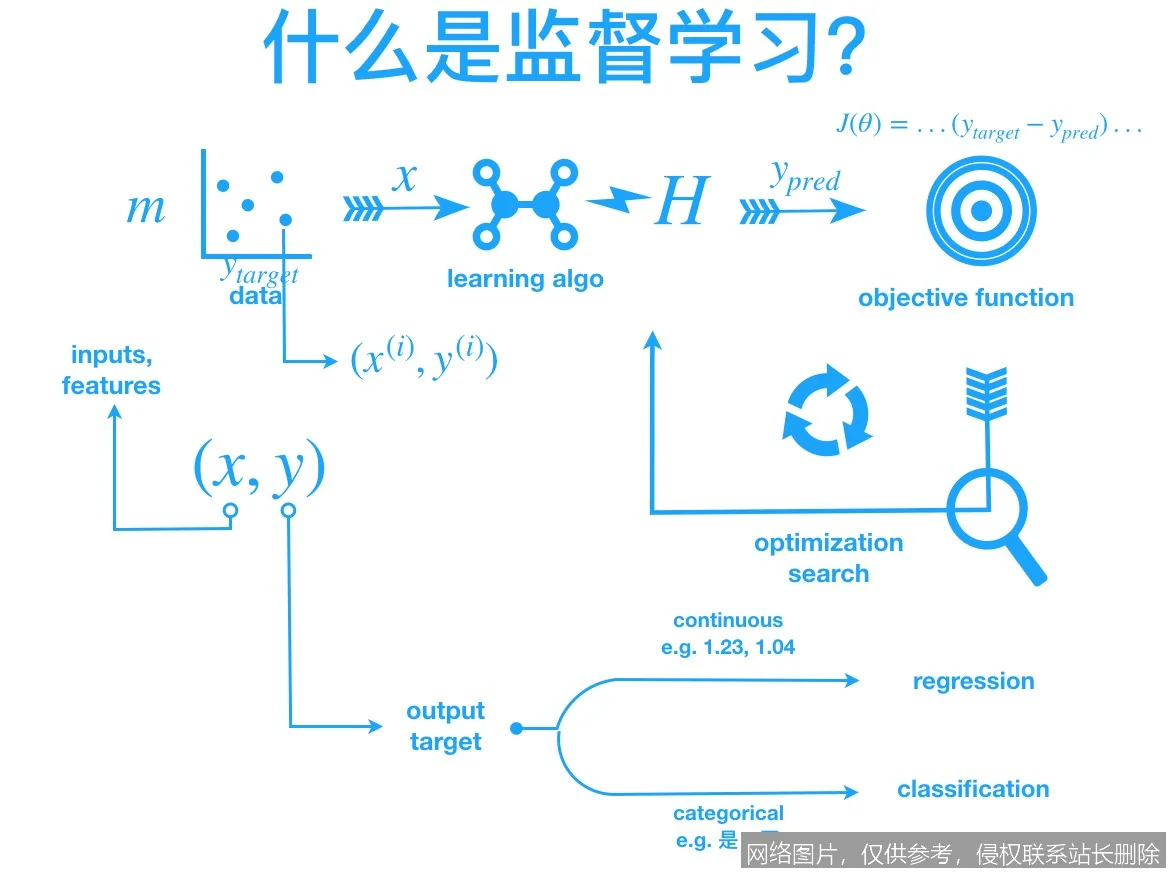
具体技术流程是:首先准备高质量的标注数据集,每个样本都由输入向量和对应的标签组成。然后,算法(如线性回归、决策树、神经网络)被初始化,并在数据集上进行迭代训练。在每次迭代中,算法根据当前模型做出预测,计算预测值与真实标签之间的差距(即损失),并通过优化算法(如梯度下降)调整模型内部的参数,以最小化这个差距。这个过程反复进行,直到模型在训练数据上的表现达到预期,或满足停止条件。
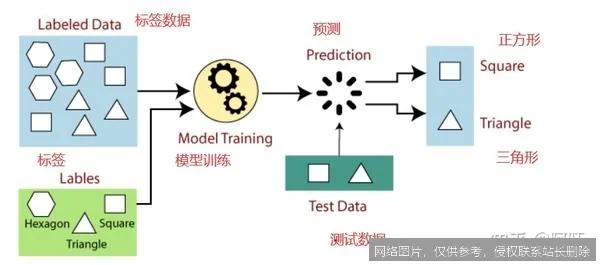
监督学习的应用场景
- 图像识别与分类:这是监督学习的经典应用。例如,给算法提供数百万张已被人工标记为“猫”、“狗”、“汽车”的图片,算法学习后,便能自动识别新图片中的物体。人脸识别、医疗影像分析(如从X光片中识别病灶)也基于此原理。
- 自然语言处理:在垃圾邮件过滤中,算法通过学习大量已被标记为“垃圾邮件”或“正常邮件”的文本数据,掌握垃圾邮件的词汇和模式特征,从而自动过滤新邮件。情感分析、机器翻译的初期模型也严重依赖监督学习。
- 预测与回归分析:在金融风控领域,利用客户的历史数据(如年龄、收入、信用记录)和对应的“是否违约”标签,训练模型以预测新客户的违约风险。房价预测、销售额 forecasting 等连续值预测问题也属于此类。
相关术语
与监督学习密切相关的概念包括:无监督学习(学习无标签数据中的结构)、半监督学习(结合少量标注数据和大量无标注数据进行学习)、分类(预测离散标签)、回归(预测连续数值)、过拟合(模型过度记忆训练数据细节而丧失泛化能力)以及损失函数(衡量模型预测错误的程度)。
延伸阅读
若想深入了解监督学习,建议从经典的机器学习教材入手,如周志华教授的《机器学习》(俗称“西瓜书”)。同时,可以在Kaggle、天池等数据科学竞赛平台上,找到丰富的标注数据集和实战项目(如泰坦尼克号生存预测、手写数字识别),通过实践巩固理论。对于希望深入算法细节的学习者,Andrew Ng在Coursera上的《机器学习》课程依然是极佳的起点。