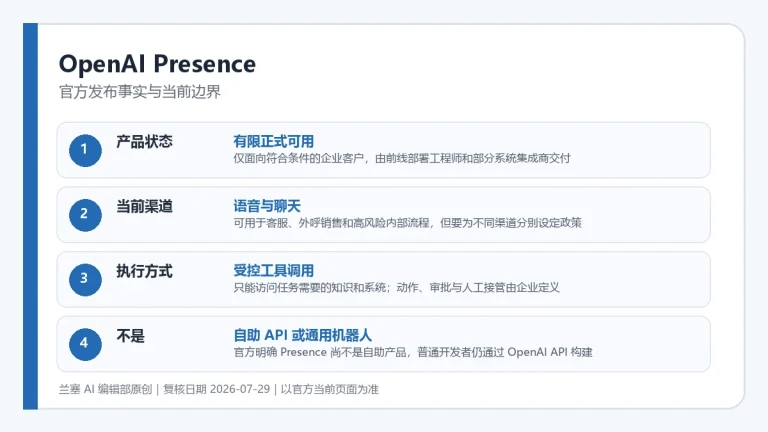
GPT是什么?
GPT(生成式预训练Transformer模型)是一种基于Transformer架构的大规模语言模型,其核心能力是通过预训练学习海量文本数据中的规律,从而能够理解并生成高质量、连贯的人类语言文本。 它代表了当前自然语言处理领域的主流技术范式,其“生成式”与“预训练”的特性,使其区别于早期的规则式或特定任务型AI模型。
原理:GPT如何工作?
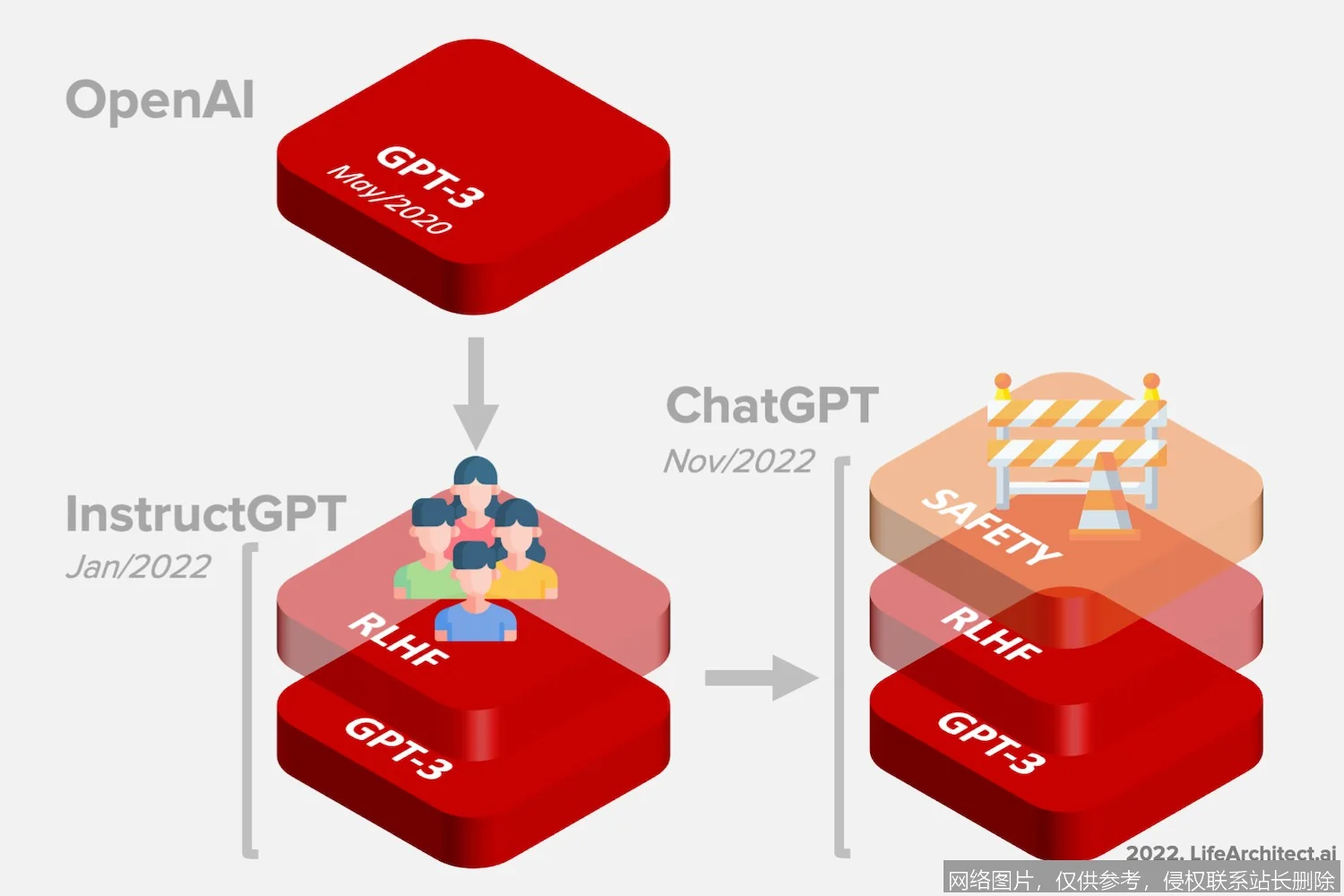
可以将GPT的工作原理类比为一个博览群书、并接受了极致完形填空训练的“超级大脑”。其工作流程分为两个关键阶段:
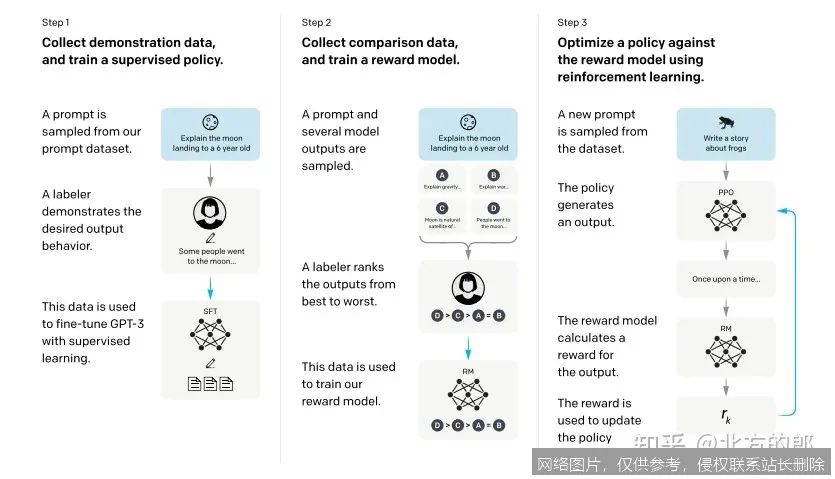
首先,在预训练阶段,模型会“阅读”互联网规模的文本数据(如书籍、网页)。它的核心训练任务是“预测下一个词”:给定一段文本序列,模型需要不断猜测被掩盖掉的下一个词是什么。通过海量数据的反复练习,模型不仅记住了词汇和语法,更深刻地掌握了世界知识、逻辑关系和语言风格。这一阶段构建了模型通用的语言理解基础。
其次,在微调或提示工程阶段,开发者可以通过给模型提供特定指令和示例(即“提示”),引导这个“通才”模型专注于执行特定任务,如回答问题、编写代码或创作诗歌。模型基于预训练阶段学到的庞大知识库,根据当前输入的上下文,计算出概率最高的下一个词序列,从而生成连贯的回复。
应用场景
- 智能内容创作与辅助:GPT能够协助用户撰写邮件、报告、营销文案、小说初稿,或进行翻译、润色与总结,大幅提升文本处理效率。
- 智能对话与客服系统:作为聊天机器人的核心引擎,GPT能够提供拟人化的、上下文感知的对话交互,应用于客户服务、虚拟助手、教育辅导等场景。
- 代码生成与编程辅助:GPT能够理解自然语言描述的需求,自动生成代码片段、解释代码功能或调试错误,成为开发者的高效编程伙伴。
相关术语
理解GPT,可以关联以下核心概念:Transformer架构(GPT依赖的核心神经网络结构)、大语言模型(LLM,GPT所属的模型类别)、预训练与微调(GPT的两阶段训练范式)、提示工程(引导GPT完成任务的关键技术)、注意力机制(使模型能关注文本关键部分的技术)。
延伸阅读
若想深入了解GPT及大语言模型的技术演进,建议从谷歌研究院提出的原始Transformer论文《Attention Is All You Need》入手。同时,可以关注OpenAI、DeepMind等机构的官方技术博客,它们通常会发布模型架构的详细解读。对于非技术背景的读者,许多科技媒体对GPT系列模型的发展史和应用前景有深入浅出的系列报道。