
OpenAI 训练数据集体诉讼复盘:P.M. 案指控、案号与自愿撤诉
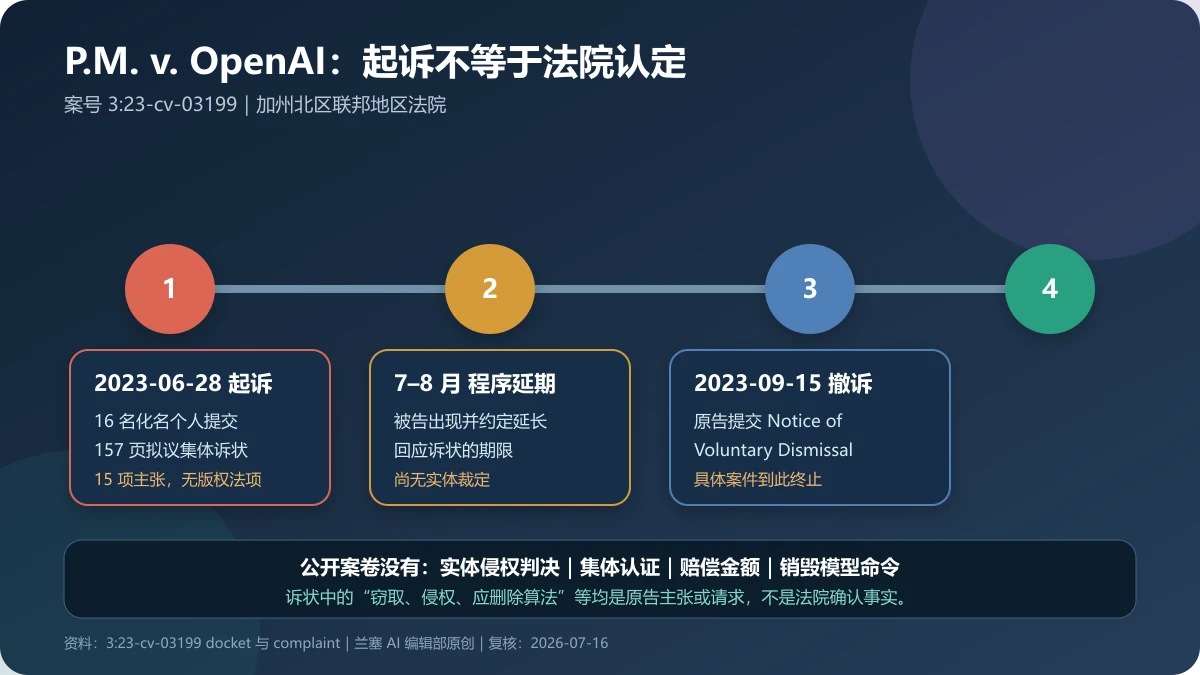
核验结论:旧稿所指的是 P.M. et al. v. OpenAI LP et al.,案号 3:23-cv-03199。16 名化名个人于 2023 年 6 月 28 日在美国加州北区联邦地区法院起诉 OpenAI 多个实体与 Microsoft,157 页诉状提出 15 项隐私、电子通信、计算机访问、消费者保护与普通法主张,没有单列《美国版权法》侵权请求。公开案卷显示,原告于 2023 年 9 月 15 日提交自愿撤诉通知;这起具体案件没有公开的实体侵权判决、集体认证、赔偿裁决或销毁模型命令。
本文保留原 URL,是为了修正已经传播的“OpenAI 遭作者版权集体诉讼并可能销毁模型”叙述。资料复核日期为 2026 年 7 月 16 日;主要证据是该案的公开 docket 记录与Document 1:Class Action Complaint。本文是案件材料说明,不构成法律意见。
这起案件的身份是什么?
| 字段 | 可核验信息 | 为什么重要 |
|---|---|---|
| 案件名称 | P.M. et al. v. OpenAI LP et al. | 不能与 Tremblay、Silverman、Authors Guild 或 New York Times 案混为一案 |
| 案号 | 3:23-cv-03199 | 同名公司诉讼很多,案号是最稳定的核验入口 |
| 法院 | U.S. District Court for the Northern District of California | 决定适用的联邦程序与管辖背景 |
| 提交日期 | 2023-06-28 | 旧稿没有年份,导致 2026 年页面被误读为新案 |
| 原告 | P.M.、K.S. 等 16 名化名个人,声称代表拟议类别 | 不是已经由法院认证的集体,也不能统一称为作者版权人 |
| 被告 | OpenAI 多个实体、OpenAI Startup Fund 相关实体与 Microsoft | 诉状的不同主张面向多个公司主体,不能笼统写成“ChatGPT 被告” |
| 最后关键程序 | 2023-09-15 原告提交 Notice of Voluntary Dismissal | 说明该具体案件没有继续到公开实体判决 |
查美国联邦案件时,可在PACER Case Locator按案号和法院进一步核对;公开聚合 docket 方便阅读,但可能提示需要到 PACER 获取更完整或更新的文件。报道时应同时写案件名称、法院、案号和材料截止日,不能只写“OpenAI 又被告了”。
案件从起诉到撤诉经历了什么?
| 日期 | Docket 事件 | 法律新闻可得出的结论 | 不能得出的结论 |
|---|---|---|---|
| 2023-06-28 | Document 1:原告提交拟议集体诉状 | 原告正式提出主张和救济请求 | 法院尚未确认任何指控为真 |
| 2023-06-29 | 书记官签发传票 | 案件进入送达和回应阶段 | 签发传票不是支持原告实体主张 |
| 2023-07-20 至 07-25 | OpenAI 与 Microsoft 律师出现,双方约定延长回应期限 | 被告参与程序并准备回应 | 延期不表示承认责任或准备和解 |
| 2023-08-31 | 法院批准继续延长被告回应期限 | 回应时间发生程序性调整 | 法院仍未判断 15 项请求是否成立 |
| 2023-09-15 | Document 38:原告提交自愿撤诉通知 | 该具体案件不再沿原 docket 继续审理 | 不能写成法院判 OpenAI 胜诉或原告败诉 |
公开 docket 的 Document 38 标题是“NOTICE of Voluntary Dismissal”。仅凭标题不能擅自补写“和解”“败诉”“有偏见驳回”或“法院认定指控无依据”;若需要判断撤诉是否排除未来同类诉讼,应阅读通知全文并结合Federal Rules of Civil Procedure及具体案件记录。对普通读者最稳妥的结论是:原告主动终止了这起案件,公开案卷没有形成实体裁定。
旧稿哪些说法把“指控”写成了“事实”?
| 旧稿说法 | 核验结果 | 正确写法 |
|---|---|---|
| “美国时间 6 月 28 日突发” | 缺少年份且页面发布于 2026 年 | 案件提交于 2023 年 6 月 28 日 |
| “多位匿名作者和版权持有者” | 诉状列的是 16 名化名个人,没有统一描述为作者或版权人 | 写明化名原告及拟议类别,不虚构职业身份 |
| “ChatGPT 训练数据版权侵权集体诉讼” | 15 项请求中没有 Copyright Act cause of action | 这是以隐私、数据抓取和消费者保护为中心的广泛诉讼 |
| “法院面临关键版权对决” | 案件在被告回应期限内被原告自愿撤诉 | 法院没有就实体问题作出公开裁定 |
| “要求销毁所有模型” | 诉状请求删除或补偿相关数据/算法、冻结商业访问等救济 | 只能说原告提出广泛禁令请求,法院没有签发这些命令 |
| “可能赔偿数十亿美元” | 诉状请求金额待审判确定,没有法院确认金额 | 不得把推测性规模写成可能判赔数字 |
诉状多次使用 “stolen”“theft”等强烈用语。这些词属于原告的法律理论和事实指控,应使用“原告声称”“诉状主张”作为归属。没有实体裁定时,本站不能把当事人用词改写成“OpenAI 已窃取”“法院确认侵权”。如何把单方材料拆成可核验主张,可参考AI 产品证据与风险评估方法和安全新闻事实核验案例。
诉状的 15 项请求到底是什么?
| 分组 | 诉状列出的请求 | 相关法源入口 | 是否有法院实体裁定 |
|---|---|---|---|
| 联邦电子通信与计算机访问 | ECPA、CFAA | 18 U.S.C. §2510;18 U.S.C. §1030 | 无 |
| 加州隐私与消费者保护 | CIPA、UCL、加州宪法隐私、侵入私人领域 | Cal. Penal Code §631;Cal. BPC §17200 | 无 |
| 伊利诺伊州请求 | BIPA、两项消费者欺诈/商业行为请求 | Illinois BIPA;Illinois Consumer Fraud Act | 无 |
| 财产与普通法理论 | 过失、侵权隐私、侵入私人领域、收受被盗财产、conversion、不当得利、未警告 | Cal. Penal Code §496及诉状引用的普通法理论 | 无 |
| 纽约消费者保护 | New York General Business Law §349 | N.Y. GBL §349 | 无 |
这张表只说明原告把哪些法律名称写进诉状,不代表每项请求满足管辖、主体资格、损害、因果关系或法律构成要件。尤其是 ECPA、CFAA、BIPA 和州法请求各有独立适用条件;没有法院意见时,不能根据诉状页数或引用法律数量判断胜算。
为什么它不是旧稿所说的“作者版权诉讼”?
判断是否为版权侵权案,最直接的方法不是在正文搜索“copyrighted”“books”或“pirated”,而是看 complaint caption、cause of action 和 prayer for relief。P.M. 诉状的 15 项请求没有列出 Copyright Act infringement;它把网络抓取、ChatGPT 用户数据、插件、Microsoft 集成、未成年人和个人信息放在同一套广泛理论中。
| 判断点 | P.M. 案 | 典型作者版权案 |
|---|---|---|
| 原告身份 | 16 名化名个人,强调网络活动、ChatGPT 使用或个人信息 | 作者或权利人通常会识别具体作品与权属 |
| 核心法条 | 电子通信、计算机访问、隐私、消费者保护和普通法 | 17 U.S.C. Copyright Act 及直接/替代/贡献侵权理论 |
| 具体作品 | 不是围绕一组已登记作品逐项主张复制 | 通常列出书籍、文章、登记或输出相似性 |
| 核心损害 | 个人信息被抓取、追踪、使用和商业化 | 受保护表达被复制、用于训练或输出 |
| 程序结局 | 2023-09-15 原告自愿撤诉,无实体裁定 | 不同案件各自有驳回、发现、简易判决或审理进度 |
同一天提交的Tremblay et al. v. OpenAI,3:23-cv-03223才是作者围绕书籍训练提出的独立案件;Silverman et al. v. OpenAI,3:23-cv-03416也是另一条版权案线。把这些案件混成一个“P.M. 版权集体诉讼”,会导致案号、原告、法条和程序状态全部错位。
原告请求了什么,法院实际给了什么?
| 诉状请求 | 属于什么 | 公开案卷中是否获得 |
|---|---|---|
| 临时冻结产品商业访问和开发,直至建立多项治理措施 | 原告请求的禁令救济 | 没有公开命令授予 |
| 建立 AI Council、问责协议和威胁管理计划 | 原告设计的治理性救济 | 没有公开命令授予 |
| 允许用户退出数据收集,删除或补偿数据及相关算法 | 原告请求的数据/算法处置 | 没有公开命令授予 |
| 建立由产品收入比例注资的 AI Monetary Fund,发放“data dividends” | 原告请求的补偿机制 | 没有建立 |
| 删除、销毁或清除相关类别成员的 PII/PHI | 原告请求的个人数据救济 | 没有公开命令授予 |
| 实际、法定、惩罚、三倍损害赔偿、返还、利息和律师费 | 金额待审判或法院确定的请求 | 没有赔偿裁决 |
“请求”与“获得”是法律报道最容易混淆的两个词。原告确实提出了非常广泛的产品、算法、数据和资金救济,但 docket 最后显示的是原告自愿撤诉,而不是法院签发禁令。旧稿所说“要求销毁所有基于这些数据训练的模型”也不精确:诉状文字包含删除或补偿数据及由其建立的 algorithms、清除 PII/PHI 等请求,但不能简化成法院要求销毁全部 GPT 模型。
“自愿撤诉”意味着 OpenAI 胜诉了吗?
不能直接这样写。自愿撤诉是程序事件,实体胜负取决于是否存在法院判决、撤诉通知内容、是否有和解及其他记录。公开 docket 的条目只足以确认原告提交了撤诉通知;它没有显示法院审理证据后认定 OpenAI 不承担责任,也没有确认原告指控成立。
| 可说 | 不可说 | 需要额外材料才能说 |
|---|---|---|
| 原告于 2023-09-15 提交自愿撤诉通知 | 法院判 OpenAI 无罪或胜诉 | 撤诉是否有条件、是否有未公开和解 |
| 公开 docket 没有实体责任判决 | 法院确认训练数据合法 | 通知是否注明有无 prejudice |
| 没有集体认证命令 | 所有潜在类别成员请求均被驳回 | 原告是否在其他案件提出相同或不同请求 |
| 没有赔偿或销毁模型命令 | 诉状内容已被法院逐项否定 | 当事人撤诉的商业、证据或策略原因 |
“拟议集体诉讼”也不等于“已经成为集体诉讼”。原告可以在 complaint 中请求代表类别,但法院通常需要另行判断人数、共同问题、典型性和代表充分性。P.M. 案的公开 docket 没有走到集体认证命令,因此文章应称“拟议集体诉讼”或“原告寻求集体诉讼地位”。
怎样区分 P.M. 案与其他 OpenAI 训练数据案件?
| 案件 | 主要原告与主题 | 核验时不要混用 |
|---|---|---|
| P.M. v. OpenAI,3:23-cv-03199 | 16 名化名个人;隐私、抓取、用户数据、插件与消费者保护 | 本页案件;2023-09-15 自愿撤诉 |
| Tremblay v. OpenAI,3:23-cv-03223 | 书籍作者;版权与训练数据 | 不能把作者身份和版权请求移植到 P.M. 案 |
| Silverman v. OpenAI,3:23-cv-03416 | 书籍作者;独立版权诉状 | 案号、作品和程序文件不同 |
| Authors Guild v. OpenAI,1:23-cv-08292 | 多名知名作者;纽约联邦法院版权案 | 提交时间、法院、原告和 docket 都不同 |
| New York Times v. Microsoft/OpenAI,1:23-cv-11195 | 新闻机构;文章版权与输出 | 不能用该案后来的裁定解释 P.M. 案结局 |
相关案件会合并、移送、修改诉状或产生新命令,状态变化很快。阅读时始终以当前 docket 和具体文件为准,不用“OpenAI 版权案有进展”覆盖所有案件。站内的ChatGPT 2023 数据暴露事件复盘则是产品隔离故障,不是训练数据诉讼;二者同样涉及“数据”,但事实、责任和处置完全不同。
读 AI 诉讼新闻,怎样避免被标题误导?

- 锁定案号:同一公司可能同时面对几十起案件,先确认法院与案号。
- 读 caption:确认原告、被告和诉状性质,不从新闻标题猜原告身份。
- 读 causes of action:正文出现“版权”不等于诉讼提出版权法请求。
- 分离 allegation 与 holding:“原告指控”“被告抗辩”“法院裁定”必须使用不同动词。
- 追 docket:检查修改诉状、延期、合并、撤诉、驳回、发现和上诉事件。
- 读 relief:分清原告想要什么、法院授予什么、最终执行什么。
- 写截止日期:法律程序会变化,文章必须标明 docket 复核日。
同样的方法适用于 AI 模型发布、安全报告和产品声明:先确定材料层级,再写结论。站内Prompt Engineering 工程指南中的主张—证据结构,以及AI 知识与工作流治理指南中的来源、版本和审计轨迹,都可以用于建立法律新闻的编辑记录。
这起案件对 AI 网站和企业有什么实际提醒?
| 对象 | 应建立的记录 | 不要做 |
|---|---|---|
| AI 新闻网站 | 案号、法院、文件编号、材料日期、主张归属和程序状态 | 把诉状标题改成“法院确认侵权” |
| 内容与数据团队 | 数据来源、许可或法律基础、抓取规则、删除与异议流程 | 把“网上公开”当成无限制使用许可 |
| AI 产品团队 | 训练、输入、日志、插件与第三方数据流的独立说明 | 用一份通用隐私政策覆盖所有处理目的 |
| 企业采购 | 产品版本、数据用途、保留、地区、管理员权限与事件响应 | 只根据模型能力决定能否输入敏感数据 |
| 法务与安全 | 诉讼保全、数据地图、责任人、供应商通知和纠错记录 | 事件发生后删除日志或用推测填补证据 |
企业要把数据来源和模型使用变成可复核流程,而不是等诉讼后再回忆。涉及工具调用和高权限执行时,可参考AI 智能体治理指南;涉及云端与本地边界时,可阅读本地 AI 与云端 AI 决策指南。这些是工程与治理建议,不替代专业法律判断。
常见问题
P.M. 案是否证明 OpenAI 非法训练 ChatGPT?
没有。诉状提出了数据抓取、隐私和财产等主张,但原告后来提交自愿撤诉通知,公开案卷没有实体责任判决。
这是不是 OpenAI 的作者版权集体诉讼?
不是准确称呼。P.M. 案有 16 名化名个人和 15 项广泛请求,没有单列 Copyright Act infringement。作者版权案件应另看 Tremblay、Silverman、Authors Guild 等具体 docket。
法院是否要求 OpenAI 销毁 GPT 模型?
没有公开命令。原告诉状请求冻结商业访问、删除或补偿相关数据/算法、删除 PII/PHI 等广泛救济,但请求不等于法院授予。
原告自愿撤诉是否代表双方和解?
公开 docket 条目本身不能证明和解。没有和解文件或当事人声明时,不应猜测撤诉原因。
“拟议集体诉讼”与“集体诉讼”有什么区别?
提交 complaint 时原告可以请求代表一个类别,但法院通常还需另行认证。P.M. 案没有公开的集体认证命令,因此不能说法院已经确认一个集体。
为什么文章仍保留原来的 URL?
该 URL 已积累浏览和可能的搜索历史。保留 URL、公开纠错并更新证据,比删除后另发一篇相似文章更有利于读者、搜索引擎和引用系统看到同一页面的修正。
编辑复核与纠错记录
编辑主体:兰塞 AI 编辑流程;事实复核:2026 年 7 月 16 日。旧稿把 P.M. 隐私与数据抓取拟议集体诉讼写成匿名作者版权案,把诉状指控写成事实,并遗漏 2023 年 9 月 15 日的自愿撤诉。本次 A 级重写依据案号 3:23-cv-03199 的公开 docket、157 页 complaint 和所列法源,区分原告主张、救济请求、程序事件与法院裁定,新增案件时间线和诉讼证据梯。本站来源、更新与纠错原则见关于本站与编辑规范。