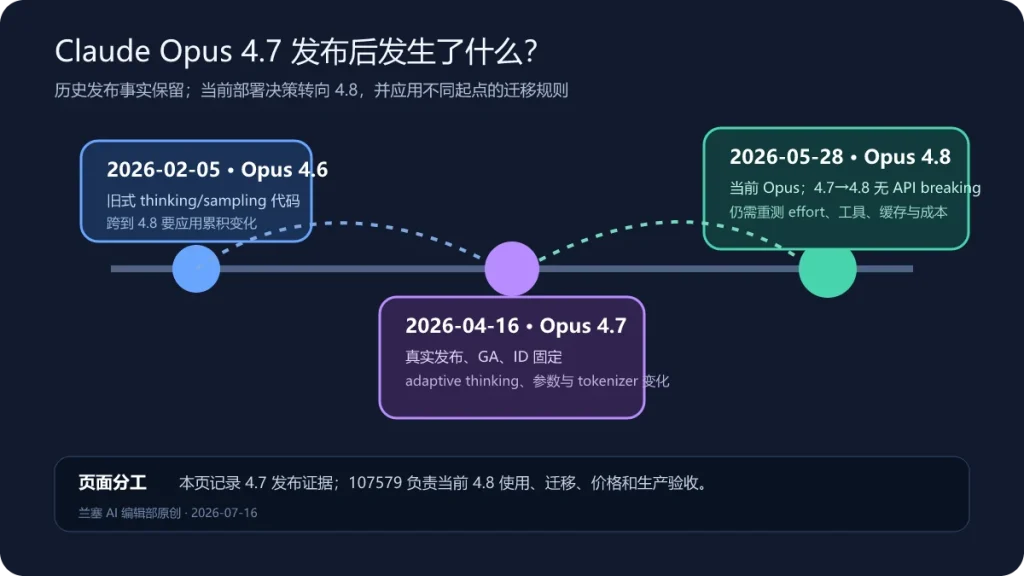
事件结论:Claude Opus 4.7 确实由 Anthropic 于 2026 年 4 月 16 日发布并进入一般可用状态,API ID 为 claude-opus-4-7。它带来了面向复杂编码、视觉和长程任务的更新,也引入了 adaptive thinking、sampling 参数限制和新 tokenizer 等迁移变化;但旧稿中的“全面领先竞品”“复杂工作可放心交付”“苹果核心伙伴专享”“未来两个月必然如何”等说法,没有足够证据或超出了来源能支持的范围。2026 年 5 月 28 日,Opus 4.8 已成为更新的 Opus 版本。
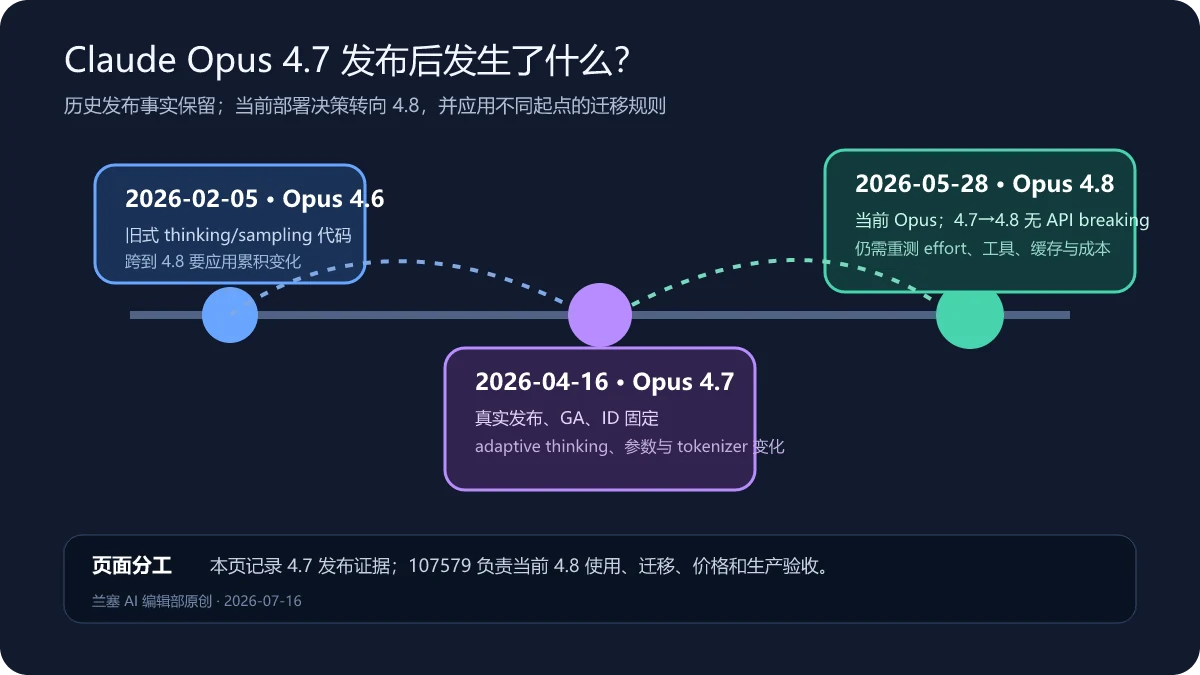
这是一篇历史发布复核,不把旧新闻改写成“刚刚”。资料复核日期为 2026 年 7 月 16 日。如果你正在选型或迁移生产系统,请直接阅读站内的Claude Opus 4.8 使用、迁移与生产验收指南;如果要理解 Anthropic 公司、Claude 产品入口、安全治理和商业数据边界,可参考Anthropic 与 Claude 公司产品指南。
Opus 4.7 的发布事实是什么?
Anthropic 的Opus 4.7 官方发布页写明发布时间为 2026 年 4 月 16 日,并称模型一般可用。发布页重点介绍高级软件工程、长程任务、视觉和专业工作,但它是供应商公告:其中 benchmark、客户引语和比较图应按原测试条件阅读,不能省略来源后改写为本站独立结论。
| 事实项 | 发布时可确认内容 | 当前阅读方式 |
|---|---|---|
| 发布日期 | 2026-04-16 | 保留原日期,不用“突发”“刚刚”制造新鲜度 |
| API ID | claude-opus-4-7 |
固定模型 ID;记录平台、区域和生命周期 |
| 发布状态 | 一般可用 | 当前仍 Active,但已有 4.8 |
| 标准价格 | 输入 5 美元/MTok、输出 25 美元/MTok | 价格可能变化,采购前查当前 Pricing |
| 主要变化 | 编码、视觉、复杂多步任务与模型行为更新 | 按自己的任务、工具和权限重新验证 |
Claude Opus 产品页已经把 Opus 4.8 列为当前型号,同时保留 4.7 的历史公告入口。历史页面的价值是回答“当时发布了什么”,而不是继续把 4.7 称为“最新旗舰”。
旧稿中的哪些主张可以确认、需要限定或应撤回?

| 旧稿主张 | 处理 | 原因 |
|---|---|---|
| 4.7 于 2026-04-16 发布 | 确认 | 官方公告可以直接支持日期与发布状态 |
| 视觉支持最长边 2576 像素 | 确认并限定 | 属于输入规格,不等于小目标识别必然正确 |
| 某些 benchmark 分数提升 | 限定 | 必须保留测试集、设置、比较版本和供应商来源 |
| 全面领先 GPT/Gemini | 撤回 | 不同模型、版本、工具和评测不可用孤立分数概括 |
| 最复杂工作可以放心交付 | 撤回 | 模型发布材料不能消除人工监督、权限和失败风险 |
| Mythos 仅向苹果等伙伴开放 | 撤回 | 官方只说明 Project Glasswing 的有限访问,不支持该名单 |
| 未来两个月将发生某次发布 | 撤回 | 旧稿预测没有来源,而且后续事实应由真实公告更新 |
旧稿还把“客户评价”“官方 benchmark”“业内观察家”和“本站判断”混成一个叙事,读者无法区分证据责任。新版要求每项可变结论能够回指官方页面或明确标为分析,不使用没有主体、日期和原文的“业内认为”。
Opus 4.7 相比 4.6,引入了哪些 API 迁移变化?
Claude Platform Migration guide把跨版本变化分得很清楚:从 4.6 或更早版本迁移到 4.7/4.8 时,不能只改模型 ID。手动 extended thinking budget 被 adaptive thinking 取代,非默认 sampling 参数会返回 400,新 tokenizer 会改变 token 计数,thinking 展示行为也发生变化。
| 4.6 旧实现 | 4.7 行为 | 应怎样迁移 | 风险 |
|---|---|---|---|
thinking.enabled + budget_tokens |
不支持,返回 400 | 改用 adaptive thinking 和 effort | 代码类型检查通过但服务端拒绝 |
| 非默认 temperature/top_p/top_k | 返回 400 | 删除字段,用提示和冻结评测控制输出 | 自动重试会重复发送同一坏请求 |
| 依赖 thinking 摘要默认返回 | 默认展示方式变化 | 核对 display 和流式 UI | 用户看到无说明的长停顿 |
| 旧 tokenizer 预算 | 相同文本 token 可能增加 | 重新调用 token counting | 费用、截断和限额超出预期 |
Adaptive thinking和Effort不是同一个概念:thinking 决定是否允许模型适应性推理,effort 控制输出层面的投入。迁移时要保存完整请求 JSON 和实际 usage,不要只看最终文字是否顺眼。
视觉与长上下文升级应该怎样解释?
Opus 4.7 发布材料强调了更高分辨率视觉输入和复杂文档任务。规格能证明接口接受一定尺寸的图像,不证明低对比度文字、细小 UI、票据、医学影像或工程图上的关键元素始终识别正确。视觉任务必须保存原图、压缩过程、提示、坐标或字段期望、实际输出和人工复核。
| 场景 | 不能只看什么 | 应怎样验收 |
|---|---|---|
| 截图和 UI | 最长边像素与单张示例 | 不同缩放、遮挡、语言、主题和细小控件 |
| PDF 与报表 | 总页数或 benchmark | 表格、脚注、扫描页、跨页引用和版本 |
| 图表理解 | 能描述趋势 | 坐标、单位、图例、数值和不确定性 |
| 浏览器智能体 | 能识别按钮 | 权限、确认、页面变化、错误恢复和审计日志 |
同样,1M 上下文是容量边界,不是事实召回和长期状态一致性的保证。需要长期编码或 Agent 流程时,可结合Claude Code 权限与实战指南,把读取、编辑、执行、网络和生产写入分开授权。
如何阅读 Opus 4.7 的 benchmark 和 System Card?
Anthropic 的System Cards 页面提供 Opus 4.7 的能力、安全评测与发布决策材料。System Card 可以帮助确认测试范围、威胁模型和已知限制,但它不是独立监管认证,也不是你的环境测试报告。发布页中的竞品对比还可能使用不同推理预算、工具、脚手架或模型快照,不能只抄最终分数。
| 阅读问题 | 必须找到的内容 | 缺失时怎么写 |
|---|---|---|
| 测的是哪个模型? | 完整 ID、日期、推理/工具设置 | 不做跨版本排名 |
| 测的是什么任务? | 数据集、评分、样本和通过条件 | 只描述测试范围,不推广到行业 |
| 谁执行测试? | 供应商、客户、第三方或本站 | 明确标为供应商材料 |
| 是否可复现? | 提示、脚手架、工具、预算和原始结果 | 不能称为独立实测 |
| 失败意味着什么? | 错误类别、影响和人工处置 | 不使用“安全”“放心交付”总括词 |
如果要比较模型,应使用站内的AI 平台统一任务评测方法,在同一输入、工具、时间和判定标准下复测;提示和版本变化的冻结方法见提示工程与版本管理指南。
Opus 4.7 的价格、token 和总成本有什么边界?
Claude Platform Pricing在复核日仍列出 Opus 4.7 标准价格为输入 5 美元、输出 25 美元/百万 token。价格相同不表示升级成本相同:tokenizer、thinking、输出长度、工具重试、缓存和人工返工都可能改变单位任务成本。
| 成本项 | 4.7 需要特别注意 | 证据 |
|---|---|---|
| 输入 token | 新 tokenizer 相对更早模型可能增加计数 | 迁移前后 count_tokens 与 usage |
| Thinking | adaptive 与 effort 改变 token 分配 | 每类任务的 thinking、质量与延迟 |
| 输出 token | 更长回答可能提高费用而非质量 | P50/P95 输出和人工删改量 |
| 工具/重试 | 失败循环、429/529 和坏参数会放大费用 | 调用链、错误码、重试次数和停止线 |
| 人工复核 | 不在 API 账单中 | 严重错误、修正时间和事故影响 |
Token counting可在请求前估算输入,但实际账单仍应读取响应 usage。若数据、费用或控制要求不适合云端,可参考本地与云端模型决策指南,不要因为 Opus 是旗舰就跳过架构比较。
Opus 4.7 现在还能使用吗?
Model deprecations在复核日把 claude-opus-4-7列为 Active,Anthropic 运营平台的暂定退休时间不早于 2027 年 4 月 16 日。伙伴云可能采用不同时间表。仍可用不等于新项目应默认选择 4.7:当前Models overview将 Opus 4.8列为更新的复杂智能体编程和企业工作型号。
| 情况 | 建议 | 理由 |
|---|---|---|
| 现有 4.7 稳定生产 | 保留回滚,canary 评估 4.8 | 4.7→4.8 无 API breaking,但行为仍需重测 |
| 新建 Opus 项目 | 优先评估 4.8,同时保留其他模型基线 | 避免刚上线即承担再次迁移 |
| 从 4.6 或更早迁移 | 直接按 4.8 累积迁移指南执行 | 不能漏掉 4.7 引入的 breaking 变化 |
| 只需要低延迟简单任务 | 同时评估 Sonnet/Haiku | 旗舰能力不等于单位任务最优 |
Opus 4.8 发布页和What’s new in 4.8说明了继任版本的新增行为。Sonnet 版本迁移的评测方法可参考站内Claude Sonnet 迁移指南,但不同系列的价格、参数和生命周期不能机械套用。
发布新闻怎样避免再次变成低质模板?
- 保留事件日期:新闻页不靠更新日期伪装新事件。
- 拆分事实与评价:公告、System Card、客户引语和编辑判断分别标明。
- 保留测试边界:benchmark 必须带模型、设置、来源和复核日期。
- 增加当前状态:出现继任版本后,在旧页说明当前型号和迁移入口。
- 删除失效预测:预测到期后用事实更新,不能继续留作“未来展望”。
- 避免绝对影响:不得用“颠覆、领跑、放心交付、扫清障碍”替代证据。
新闻内容与 evergreen 指南应互相链接但不互相复制。本页记录 4.7 发布与纠错;107579 负责当前 Opus 4.8 的参数、价格、迁移和生产验收。这样搜索引擎与读者都能明确页面职责。
团队怎样复核一篇模型发布稿,而不是再次批量改写公告?
高质量发布页不应只是把厂商英文公告翻译成更夸张的中文。编辑要先保存公告、模型目录、迁移文档、价格和 System Card 的复核日期,再把文章中的每个数字、比较、因果和未来判断拆成原子主张。只有原文能够完整支持的主张才能写成事实;只能部分支持的内容必须缩小范围;找不到来源或已经到期的预测应删除。
| 复核阶段 | 具体动作 | 交付证据 | 不合格表现 |
|---|---|---|---|
| 事件身份 | 确认官方 URL、发布日期、模型 ID、发布状态和作者主体 | 公告快照与复核日期 | 只引用媒体转载或搜索摘要 |
| 规格核对 | 把价格、上下文、输出、平台和生命周期回指模型目录 | 字段级来源表 | 把不同平台或不同日期拼成一个规格 |
| 数字核对 | 记录 benchmark 名称、模型快照、工具、预算和评分口径 | 可打开的原表或 System Card | 只抄最高分和竞品名称 |
| 影响判断 | 区分供应商定位、客户引语、编辑推论和本站测试 | 每条判断的责任主体 | 使用“业内认为”“必将颠覆”代替证据 |
| 当前状态 | 检查继任型号、弃用、价格和功能是否变化 | 更新说明与迁移入口 | 几年后仍称“最新、突发” |
| 发布验收 | 检查标题、摘要、图片、内链、结构化数据和移动端 | 线上 QA、纠错记录和回滚备份 | 正文改了但首页仍展示旧标题 |
例如,“Opus 4.7 在某个公开评测获得某分数”与“Opus 4.7 全面领先所有模型”不是同一主张。前者在测试设置明确时可能成立;后者需要覆盖不同任务、竞品版本、推理预算和工具配置的系统证据,通常不能由一张发布图推出。同样,客户说模型“更像同事”只能作为该客户在特定环境的主观反馈,不能改写成所有企业都会降低监督成本。
新闻更新也不能只替换型号名称。出现 Opus 4.8 后,本页仍应保留 4.7 当时的 API 变化,因为从 4.6 或更早版本迁移时,这些累积变化依然重要;但“当前应该如何选型”必须交给持续更新的 107579。这样既保存历史证据,也避免旧新闻与 evergreen 页重复竞争。
最后,纠错记录应说明删除了什么以及为什么删除,而不是只写“内容已更新”。本站此次明确撤回无可核验来源的绝对竞品排名、苹果伙伴名单、放心交付结论和未来两个月预测;保留的发布日期、ID、价格、参数与生命周期均能回指官方资料。这个过程比增加更多形容词更能提升页面被搜索引擎和 AI 系统稳定引用的可能性。
对于仍准备继续运行 4.7 的团队,历史新闻页也应承担变更提醒:保存当前模型 ID、平台和弃用通知订阅,定期复查价格、fast mode、缓存与伙伴云差异;一旦切换到 4.8,就在变更单中引用新的冻结评测和回滚结果,而不是把本页发布时的评价继续当成当前生产证据。
常见问题
Claude Opus 4.7 是虚构型号吗?
不是。Anthropic 于 2026 年 4 月 16 日正式发布,当前生命周期页面仍列为 Active。
旧稿里的所有 benchmark 都是假的吗?
不能这样概括。部分数字可能来自官方发布或 System Card,但旧稿没有逐项保留来源、模型设置和适用范围,因此不能继续以孤立数字支持普遍排名。新版只保留可核验结论。
Opus 4.7 比 4.8 更适合生产吗?
没有脱离任务的统一答案。现有 4.7 系统可以继续运行并 canary 评估 4.8;新项目通常应先评估 4.8,再用冻结任务比较质量、延迟、成本和风险。
4.7 的高分辨率视觉能替代 OCR 或规则校验吗?
不能。接口规格不等于关键字段准确。金额、日期、合同、票据和高风险图像仍应使用确定性校验、原始来源和人工复核。
编辑复核与纠错记录
本文由兰塞 AI 编辑流程于 2026 年 7 月 16 日复核。旧标题使用“突发、全面升级”,正文把供应商 benchmark、竞品排名、客户意见和编辑预测混为事实,并含“复杂工作可放心交付”“为合规扫清障碍”“Mythos 仅向苹果等伙伴开放”“未来两个月”等缺少支持或已经失效的断言。新版确认 2026-04-16 发布、API ID、一般可用状态、价格和迁移变化;把 benchmark 与视觉能力放回供应商测试边界;新增 4.8 继任状态、生命周期、token 成本、历史新闻维护规则和两张原创证据图。本站的来源、更新与纠错原则见关于本站与编辑规范。