CUDA编程揭秘:解锁GPU并行计算的极致性能
AI概念与词典
发布于 2026-04-15
CUDA:开启GPU通用计算的革命之门
在追求计算速度的征途上,CPU的单核性能提升逐渐触及物理极限。此时,一种将海量简单任务同时处理的技术——并行计算,成为了新的突破口。而NVIDIA推出的CUDA(Compute Unified Device Architecture)平台,正是这场革命的钥匙。它让开发者能够直接利用GPU中成千上万个计算核心,将原本由CPU串行处理的复杂任务,转化为GPU的并行计算盛宴,从而在科学计算、人工智能、图形渲染等领域实现了性能的飞跃。
CUDA的核心架构与编程模型
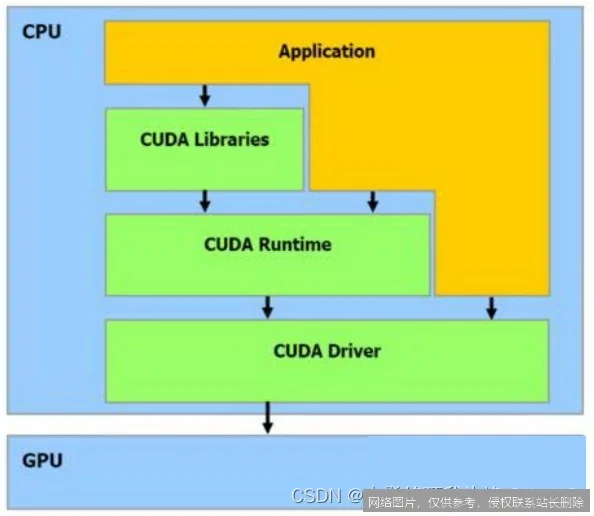
理解CUDA,首先要了解其独特的层次化架构。它将GPU视为一个强大的并行数据处理器,并抽象出几个关键概念:
- 线程(Thread):最基本的执行单元,数量庞大。
- 线程块(Block):一组线程的集合,块内的线程可以高效协作与通信。
- 网格(Grid):所有线程块的集合,构成了一个完整的CUDA内核调用。
这种“网格-块-线程”的三层模型,完美映射了GPU的物理硬件结构(流式多处理器、核心),使得程序能够高效地组织和管理数以万计的并发线程。开发者使用C/C++等语言,通过添加特殊的关键字(如__global__)来定义在GPU上运行的函数(内核),即可将计算任务“发射”到GPU上执行。

解锁极致性能的关键技术
仅仅将代码移植到CUDA上并不能自动获得最佳性能。要真正释放GPU的潜力,必须深入理解并优化几个核心方面:
- 内存层次优化:GPU拥有全局内存、共享内存、常量内存、纹理内存等多个层次。其中,共享内存是块内线程的“高速黑板”,访问速度极快。合理利用共享内存减少对全局内存的访问,是性能提升的关键。
- 线程束(Warp)调度:GPU以32个线程为一组(称为Warp)进行调度和执行。确保线程束内的线程执行相同的指令路径(避免分支发散),可以最大化硬件利用率。
- 隐藏内存延迟:通过启动足够多的线程块,当一个线程束因等待数据而停顿时,GPU可以立即切换到另一个就绪的线程束执行,从而将内存访问延迟“隐藏”在计算之下。
CUDA的应用领域与未来展望
如今,CUDA已远远超越了图形处理的范畴,成为加速通用计算的行业标准。它在以下领域大放异彩:
- 人工智能与深度学习:训练复杂的神经网络模型需要巨大的矩阵运算量,CUDA核心正是此类计算加速的基石。
- 科学模拟:气候建模、流体动力学、分子动力学等模拟涉及大量并行计算单元,GPU可提供远超CPU集群的计算能力。
- 金融分析:高频交易、风险评估中的蒙特卡洛模拟等,都能通过CUDA实现实时或准实时计算。
展望未来,随着异构计算成为主流,CUDA生态将持续进化。它不仅支持更先进的GPU架构,也通过库如cuDNN、cuBLAS,以及平台如NVIDIA RAPIDS,不断降低开发门槛,让更多领域的工程师和科学家能够轻松驾驭并行计算的强大力量,持续推动计算技术的边界。
相关推荐
- Precision 精确率是什么?公式、Recall 区别与阈值选择指南
- VLM 是什么?视觉语言模型原理、任务选型、评测与生产验收指南
- 注意力机制是什么?QKV、Mask、多头与长上下文完整指南
- DeepSeek-R1 是什么?R1-Zero、训练流程、蒸馏模型与本地部署指南
- 声音克隆是什么?TTS/VC 原理、授权、识别与上线验收指南
- 大模型微调是什么?从数据到 LoRA/QLoRA 与上线验收
- 深度学习优化器是什么?SGD、AdamW、Muon 选择与调参指南
- DeepSeek‑V3.2 是什么?发布时间、Agent能力、Speciale、开源权重与V4现状
- 困惑度(Perplexity)是什么?公式、计算方法与 LLM 评估陷阱
- Arena(原 LMArena)是什么?排行榜原理、偏差与模型选型指南