一句话定义
HellaSwag 是一个极具挑战性的人工智能常识推理基准,旨在通过让模型预测故事的最合理结局,来评估其是否真正具备人类般的语境理解与逻辑推断能力。
在人工智能飞速发展的今天,我们常常听到关于大语言模型(LLM)“智商”的讨论。然而,如何科学、客观地衡量一个模型是否真的“理解”了世界,而不仅仅是记住了海量的文本数据?这就引出了我们今天的主角——HellaSwag。它不仅仅是一个数据集,更是检验 AI 是否具备“常识”的试金石。本文将深入剖析 HellaSwag 的定义、技术原理、核心概念、实际应用以及未来的演进路径,帮助读者系统性地掌握这一关键术语。
技术原理:从统计概率到常识推理的跨越
HellaSwag 的全称是"Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations"(具有对抗性生成的困难结局、长上下文和少样本活动情境)。这个名字虽然拗口,却精准地概括了其核心技术机制。要理解 HellaSwag 的工作原理,我们需要拆解其构建逻辑、评估方式以及它与传统测试方法的本质区别。
1. 核心工作机制:对抗性过滤(Adversarial Filtering, AF)
HellaSwag 最革命性的创新在于其数据生成方法——对抗性过滤(Adversarial Filtering, AF)。在 HellaSwag 出现之前,许多常识推理数据集(如 ROCStories)的干扰项(即错误选项)往往很容易排除。早期的 AI 模型只需利用简单的词汇重叠或浅层的语法线索,就能以极高的准确率猜出正确答案,而无需真正理解故事的逻辑。
为了解决这个问题,HellaSwag 的创作者设计了一套巧妙的“猫鼠游戏”:
- 第一步:生成候选项。首先,利用一个强大的生成模型(最初是基于 LSTM 或早期 Transformer 的模型),根据给定的上下文(Context),生成多个可能的故事结局。其中一个是来自真实人类标注的正确结局(Gold Ending),其余则是模型生成的干扰项(Distractors)。
- 第二步:训练判别器。接着,训练一个判别模型去区分哪个是正确结局,哪个是生成的干扰项。如果判别器能轻松分辨,说明这些干扰项太假了,不具备迷惑性。
- 第三步:迭代筛选。这是最关键的一步。系统会保留那些能够“骗过”当前最强判别器的干扰项。换句话说,只有当生成的错误选项在统计学特征上与正确选项极度相似,以至于现有的 AI 模型都无法轻易区分时,这个样本才会被纳入 HellaSwag 数据集。
- 第四步:循环往复。随着判别器变得越来越强,生成器也必须生成更高质量、更符合逻辑但事实上错误的干扰项。经过多轮迭代,最终留下的都是“硬骨头”。
这种机制确保了 HellaSwag 中的每一个问题,对于依赖表面统计规律的模型来说都是极难的。模型必须真正理解上下文的语义流、人物的动机以及物理世界的常识,才能做出正确选择。
2. 关键技术组件解析
HellaSwag 的运作依赖于几个关键的技术组件,它们共同构成了一个严密的评估闭环:
- 上下文(Context):通常是一段描述日常活动或情境的视频字幕或文本段落,长度适中,提供了推理所需的背景信息。例如:“一个人走进厨房,打开冰箱,拿出鸡蛋……"
- 起始句(Starters):为了增加难度,部分样本会提供不同的起始引导,测试模型在不同切入点下的推理稳定性。
- 四选一选择题(Multiple Choice):每个样本包含一个正确结局和三个通过 AF 算法生成的对抗性干扰项。这四个选项在长度、词汇分布和语法结构上高度相似,消除了模型通过“找不同”(如长度异常、生僻词)来作弊的可能。
- 零样本与少样本学习(Zero-shot & Few-shot Learning):HellaSwag 特别强调在不进行特定任务微调(Fine-tuning)的情况下测试模型的能力。这迫使模型依靠预训练阶段学到的通用知识进行推理,从而更真实地反映其“常识”水平。
3. 与传统方法的对比:为什么旧的基准失效了?
在 HellaSwag 诞生之前,业界常用的基准测试如SWAG (Situations With Adversarial Generations) 已经引入了一些对抗性生成的概念。然而,随着 BERT 等预训练模型的出现,SWAG 很快就被“刷爆”了,模型准确率迅速接近人类水平。这是因为 SWAG 中的干扰项虽然经过了一定筛选,但仍存在明显的模式漏洞。
我们可以用一个类比来理解这种差异:

想象我们在测试一个学生是否读懂了一篇小说。
- 传统方法(如早期数据集):错误选项非常离谱。比如故事讲的是“做饭”,错误选项却是“他飞上了月球”。学生不需要读懂故事,只要看到“月球”觉得不对劲就能选对。这测的是“词汇匹配”,不是“阅读理解”。
- SWAG 方法:错误选项变得合理了一些。比如“他把鸡蛋打碎在碗里”vs“他把鸡蛋壳扔进了垃圾桶”。两者都相关,但逻辑上有细微差别。聪明的学生(早期 AI)可以通过统计哪个词组在训练数据中出现频率更高来猜对。
- HellaSwag 方法:错误选项是经过精心设计的“陷阱”。四个选项读起来都非常通顺,甚至都符合语法和部分逻辑。例如:
- A: 他把鸡蛋打在碗里,开始搅拌。(正确,符合烹饪流程)
- B: 他把鸡蛋打在桌上,开始擦拭。(看似合理,但不符合“拿出鸡蛋”后的常规意图)
- C: 他把鸡蛋放回冰箱,关上了门。(语法完美,但与“拿出”的动作流冲突)
- D: 他把鸡蛋壳剥开,直接吞了下去。(极端情况,但在某些语境下可能,需结合前文判断)
在 HellaSwag 的场景下,学生必须真正理解“做饭”这个脚本(Script),知道通常的步骤是什么,才能排除那些看似合理实则荒谬的选项。这就是 HellaSwag 的核心价值:它将评估的重点从语言建模能力(Language Modeling)转移到了常识推理能力(Commonsense Reasoning)。
核心概念:构建常识推理的知识图谱
要深入理解 HellaSwag,我们必须厘清与其紧密相关的几个核心概念。这些概念不仅构成了 HellaSwag 的理论基础,也是当前自然语言处理(NLP)研究的前沿热点。
1. 关键术语解释
- 常识推理(Commonsense Reasoning):指利用人类在日常生活中习得的、未言明的背景知识进行推断的能力。例如,“如果杯子掉在地上,它可能会碎”。这种知识很少被明确写在书本里,但人类天生具备。HellaSwag 正是为了测试 AI 是否拥有这种隐性知识。
- 脚本知识(Script Knowledge):由心理学家 Roger Schank 提出,指人们对常见事件序列的结构化认知。例如,“去餐厅吃饭”的脚本包括:进门、点餐、吃饭、结账、离开。HellaSwag 的大量样本基于此类日常活动脚本,测试模型是否能预测序列的下一步。
- 对抗性样本(Adversarial Examples):指经过特殊设计、旨在误导机器学习模型的输入数据。在 HellaSwag 中,对抗性样本特指那些由生成模型创建、专门用来混淆判别模型的错误结局。
- 泛化能力(Generalization):指模型在面对未见过的数据时的表现能力。HellaSwag 通过严格的对抗性过滤,确保测试集中的样本分布与训练集有显著差异,从而严格检验模型的泛化能力,防止过拟合(Overfitting)。
2. 概念关系图谱
我们可以将 HellaSwag 置于一个更大的概念网络中来理解其位置:
目标层:通用人工智能(AGI) -> 需要 -> 核心能力:常识推理 -> 依赖 -> 知识类型:脚本知识/物理常识/社会常识。
评估层:为了量化上述能力 -> 需要 -> 基准测试(Benchmarks):SuperGLUE, BIG-Bench, HellaSwag。
方法论层:构建高质量基准 -> 采用 -> 技术手段:对抗性过滤(AF) -> 产生 -> 数据类型:高难度四选一选择题。
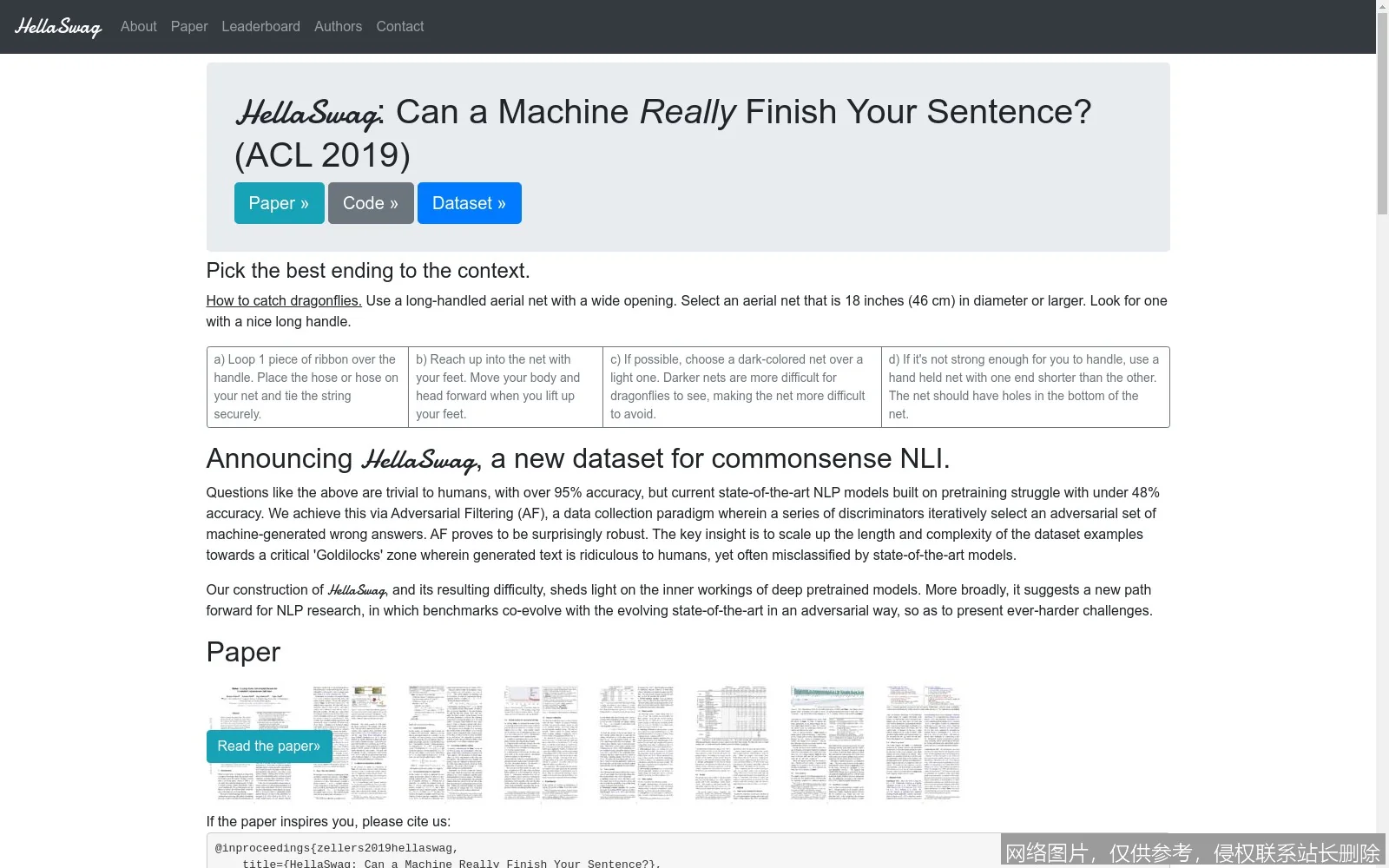
在这个图谱中,HellaSwag 处于连接“理论目标”与“工程实践”的关键节点。它不仅是测试工具,其构建过程本身也是对“什么是常识”的一次形式化探索。
3. 常见误解澄清
在学术界和工业界的讨论中,关于 HellaSwag 存在一些常见的误解,需要在此澄清:
误解一:"HellaSwag 只是另一个阅读理解数据集。”
澄清:不完全是。传统的阅读理解(如 SQuAD)通常要求模型从文中提取现成的答案。而 HellaSwag 要求模型进行“生成式”的逻辑补全,答案不在文中,而在模型的“常识库”里。它测的是推断,而非检索。
误解二:“只要模型在 HellaSwag 上得分高,就代表它有意识了。”
澄清:这是一个危险的推论。高分仅表明模型在统计规律上极好地模拟了人类的常识反应,或者说它“背诵”了足够多的类似场景模式。这并不等同于模型具备了主观意识或对物理世界有真实的感知。正如哲学家约翰·塞尔的“中文房间”论证所示,模拟理解不等于真正理解。
误解三:“对抗性过滤会让数据集偏向某种特定的模型偏见。”
澄清:这是一个值得警惕的问题。确实,AF 过程依赖于当时的生成器和判别器,如果这些基础模型本身存在偏见(Bias),生成的干扰项可能也会带有偏见。因此,现代研究在使用 HellaSwag 时,通常会结合偏差分析(Bias Analysis),并尝试使用多样化的基础模型来进行对抗生成,以减轻这一问题。
实际应用:从实验室到 2026 年的落地展望
HellaSwag 不仅仅是一个学术玩具,它在推动 AI 技术从实验室走向实际应用的过程中扮演着至关重要的角色。随着模型能力的提升,其应用场景也在不断拓展。
1. 典型应用场景
- 智能助手与对话系统(Conversational AI):
在客服机器人或个人助理(如 Siri, Alexa, 小爱同学)中,理解用户的潜台词和上下文逻辑至关重要。HellaSwag 训练出的模型能更好地预测用户下一步的需求。例如,当用户说“我好像发烧了”,模型不仅能识别关键词“发烧”,还能基于常识推理出用户可能需要“体温计”、“退烧药”或“医院建议”,而不是机械地搜索“发烧的定义”。 - 内容生成与辅助写作(Content Generation):
在自动写小说、生成剧本或辅助创作工具中,保持情节的逻辑连贯性是最大的难点。基于 HellaSwag 优化的模型可以充当“逻辑校对员”,检测故事发展是否符合常理,或者为作者提供多个合乎逻辑的情节走向建议,避免写出“主角突然会飞”这类破坏沉浸感的桥段。 - 视频理解与自动驾驶(Video Understanding & Autonomous Driving):
HellaSwag 的原始数据大量来源于视频字幕(ActivityNet Captions)。这意味着它在预测“接下来发生什么”方面具有天然优势。在自动驾驶领域,车辆需要根据当前的路况(上下文)预测其他车辆或行人的行为(结局)。一个在 HellaSwag 上表现优异的模型,更能理解“行人站在路边看手机”可能意味着“即将过马路”还是“只是在等车”,从而做出更安全的路径规划。 - 教育与自适应学习(EdTech):
在教育科技产品中,可以利用 HellaSwag 的原理生成高质量的逻辑推理题目,帮助学生锻炼思维能力。同时,AI 导师可以利用这种推理能力,更准确地理解学生的错误思路,提供针对性的辅导,而不仅仅是给出标准答案。
2. 代表性产品与项目案例
虽然很少有产品直接宣称“本产品使用了 HellaSwag 数据集”,但其背后的技术理念已深深植入主流大模型中:

- GPT-4 / Claude 3 / Gemini 系列:这些顶尖大模型在预训练和微调阶段,都广泛涵盖了包含 HellaSwag 在内的多种推理基准数据。它们在处理复杂指令、续写故事时的流畅性和逻辑性,很大程度上得益于对这类对抗性常识数据的内化。开发者在评估这些模型的版本迭代时,HellaSwag 依然是核心的监控指标之一。
- AllenAI 的 OLMo 项目:作为开源模型的代表,OLMo 在训练过程中明确强调了包含高质量的推理数据,并公开了其评估结果在 HellaSwag 上的表现,以此证明开源模型也能具备强大的常识推理能力,打破了闭源模型的垄断。
- 交互式叙事游戏引擎:一些新兴的 AI 游戏公司正在利用基于 HellaSwag 原理训练的模型,构建动态剧情生成引擎。玩家的每一个选择都会触发模型进行实时的逻辑推演,生成独一无二的、符合逻辑的故事分支,极大地提升了游戏的可玩性。
3. 使用门槛与条件:面向 2026 年的展望
随着时间推移到 2026 年,HellaSwag 的应用形态将发生显著变化:
- 从“基准”变为“基石”:到 2026 年,HellaSwag 可能不再作为一个独立的“高难度挑战”存在,因为那时的主流模型在其上的得分可能已经接近饱和(接近 95% 以上)。它将变成像“乘法口诀”一样的基础能力验证。应用的重点将转向更复杂的多模态推理(Multimodal Reasoning),即结合视觉、听觉和文本的综合常识判断。
- 低资源环境下的部署:目前的常识推理往往依赖千亿参数的大模型。2026 年的趋势将是“小型化”。通过知识蒸馏(Knowledge Distillation)技术,将大模型在 HellaSwag 上学到的推理能力迁移到端侧小模型(如运行在手机或 IoT 设备上的模型)中,使得离线状态下的智能设备也具备优秀的逻辑推断能力。
- 动态对抗评估:静态的 HellaSwag 数据集可能会被“动态 HellaSwag"取代。系统将实时生成新的对抗性样本,持续测试在线模型的鲁棒性,防止模型在长期运行中出现“逻辑退化”或被新的攻击手段绕过。
对于开发者而言,使用相关技术的门槛将降低。无需从头构建对抗性数据集,云服务商将提供预置的“常识推理中间件”,开发者只需调用 API 即可为应用赋予逻辑判断能力。但对于研究者来说,挑战将升级为:如何解决模型在极端边缘情况(Edge Cases)下的常识缺失,以及如何实现跨文化常识的迁移。
延伸阅读:通往通用人工智能的进阶之路
HellaSwag 只是 AI 常识推理宏大版图中的一块拼图。如果你想更深入地探索这一领域,以下路径和资源将为你提供指引。
1. 相关概念推荐
- SuperGLUE:一个比 GLUE 更难的自然语言理解基准集合,其中包含了 HellaSwag 以及其他多项高难度任务,是全面评估模型综合能力的必测榜单。
- BIG-Bench (Beyond the Imitation Game Benchmark):由 Google 主导的大规模基准测试,包含数千项任务,旨在探索大模型的能力边界,其中大量任务涉及复杂的常识和多步推理。
- Chain-of-Thought (CoT, 思维链):一种提示工程(Prompt Engineering)技术,通过引导模型展示推理步骤(“让我们一步一步思考”),显著提高其在包括 HellaSwag 在内的复杂推理任务上的表现。
- Neuro-Symbolic AI(神经符号人工智能):结合了神经网络的学习能力和符号逻辑的推理能力的混合架构,被认为是解决深层常识推理问题的潜在终极方案。
2. 进阶学习路径
建议按照以下顺序深入学习:
- 基础阶段:掌握 Transformer 架构原理,理解 BERT、GPT 等预训练模型的基本工作机制。阅读《Attention Is All You Need》论文。
- 进阶阶段:深入研究 NLP 评估基准。阅读 HellaSwag 的原始论文《HellaSwag: Can a Machine Really Finish Your Sentence?》,理解对抗性过滤的数学原理和实现细节。
- 高阶阶段:探索常识知识的表示与获取。研究 ConceptNet、Atomic 等常识知识库的构建与应用。关注神经符号结合的最新研究成果。
- 实战阶段:在 Hugging Face 等平台上下载 HellaSwag 数据集,尝试复现论文结果,或使用 LangChain 等框架开发基于常识推理的应用 Demo。
3. 推荐资源和文献
- 核心论文:
- Zellers, R., et al. (2019). "HellaSwag: Can a Machine Really Finish Your Sentence?" Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL). (这是必读的源头文献)
- Wei, J., et al. (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." NeurIPS. (理解如何提升推理能力的关键)
- 数据集与代码库:
- Hugging Face Datasets:
hellaswag(提供便捷的数据加载接口) - AllenAI GitHub Repository: 查找与 SWAG 和 HellaSwag 相关的开源代码实现。
- Hugging Face Datasets:
- 在线课程与社区:
- Coursera / DeepLearning.AI: "Natural Language Processing Specialization"。
- Papers With Code: 追踪 HellaSwag 榜单的最新 State-of-the-Art (SOTA) 模型及其技术报告。
结语:HellaSwag 的出现,标志着 AI 评估从“记忆力的比拼”转向了“理解力的较量”。它不仅是一个数据集,更是一面镜子,映照出当前人工智能在模仿人类常识道路上的进步与不足。随着 2026 年及未来技术的演进,我们有理由相信,基于此类基准构建的 AI 系统将变得更加聪明、可靠,真正成为人类得力的智能伙伴。对于每一位 AI 学习者而言,理解 HellaSwag,就是理解 AI 通向真正智能的关键一步。