一句话定义
交叉验证(Cross-Validation)是一种通过将数据集划分为多个子集并轮流作为测试集,以评估机器学习模型泛化能力并防止过拟合的统计重采样技术。
技术原理:从“一次考试”到“模拟实战”的进化
在人工智能与机器学习(Machine Learning, ML)的广阔领域中,如何判断一个模型是否真正“学会”了规律,而不是死记硬背了答案,是决定项目成败的关键。这就引出了我们要深入探讨的核心技术——交叉验证(Cross-Validation, CV)。要理解其精妙之处,我们需要深入其核心工作机制,剖析关键技术组件,并将其与传统方法进行对比。
核心工作机制解析:数据的轮转艺术
交叉验证的本质是一种重采样(Resampling)技术。它的核心思想非常直观:既然我们担心模型在未见过的数据上表现不佳,那就人为地制造多次“未见过的数据”场景,让模型反复接受考验。
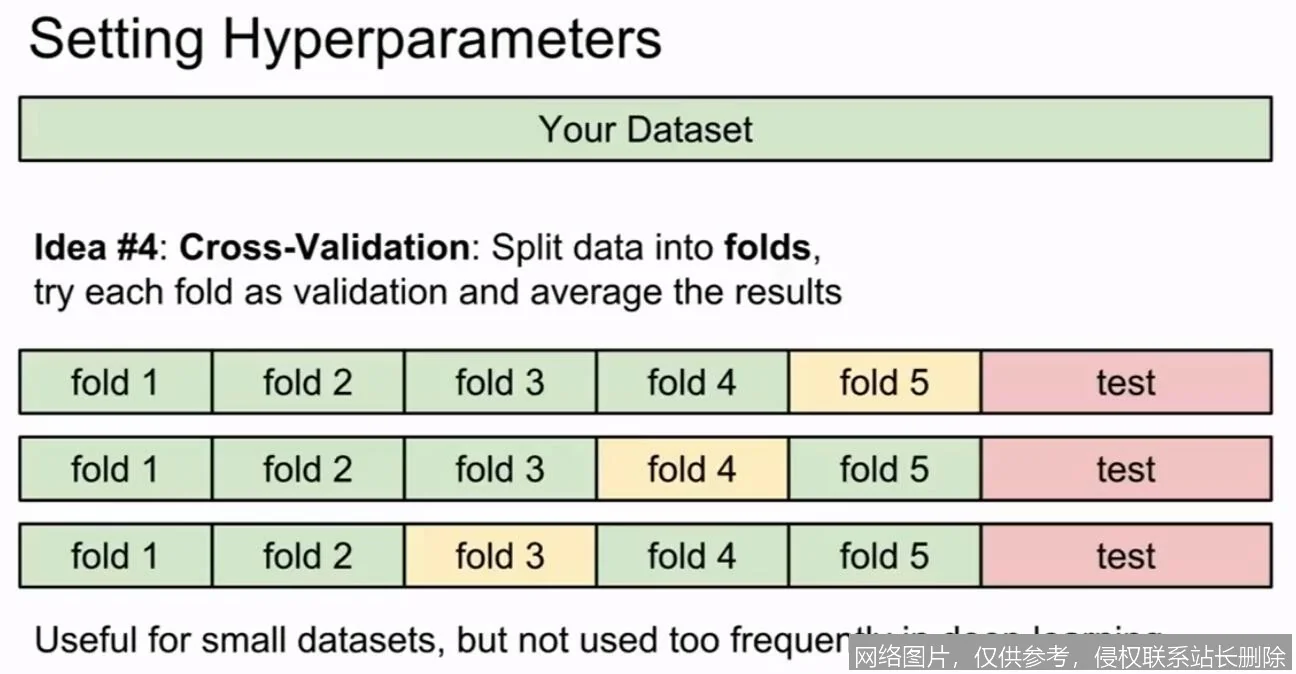
以最经典的K 折交叉验证(K-Fold Cross-Validation)为例,其工作流程如同精密的齿轮咬合:
1. 数据打乱与分割(Shuffling & Splitting):首先,将原始数据集(Dataset)随机打乱,然后均匀地切割成 K 个大小相等的互斥子集(Subsets),称为“折”(Folds)。通常 K 取值为 5 或 10。
2. 迭代训练与验证(Iterative Training & Validation):算法进行 K 次迭代。在第 i 次迭代中:
- 第 i 个子集被保留作为验证集(Validation Set),用于模拟“期末考试”。
- 剩余的 K-1 个子集合并作为训练集(Training Set),用于“日常学习”。
- 模型在训练集上进行拟合,然后在验证集上进行评估,记录性能指标(如准确率、均方误差等)。
3. 结果聚合(Aggregation):K 次迭代完成后,我们将得到 K 个性能评分。最终的模型评估结果是这 K 个分数的平均值,同时还可以计算标准差来衡量模型的稳定性。
这种机制确保了数据集中的每一个样本都恰好被用作一次验证数据,并被用作 K-1 次训练数据。这不仅最大化了数据的利用率,更重要的是,它消除了因单次随机划分数据而带来的偶然性偏差。
关键技术组件说明
要实现高效的交叉验证,几个关键组件缺一不可:
- 分层抽样(Stratified Sampling):在处理分类问题(Classification Problems)时,简单的随机分割可能导致某些折中类别分布不均(例如,某折中全是正样本,没有负样本)。分层 K 折交叉验证(Stratified K-Fold)强制要求每个折中的类别比例与原始数据集保持一致。这是保证评估结果无偏的关键。
- 随机种子(Random Seed):由于涉及随机打乱,为了保证实验的可复现性(Reproducibility),必须固定随机种子。否则,每次运行代码得到的分割结果不同,评估分数也会波动,导致无法对比不同模型的优劣。
- 嵌套交叉验证(Nested Cross-Validation):这是一个进阶组件。当我们需要同时进行模型选择(Model Selection)和超参数调优(Hyperparameter Tuning)时,普通的交叉验证会导致数据泄露(Data Leakage),使得评估结果过于乐观。嵌套交叉验证包含内外两层循环:内层循环用于寻找最佳超参数,外层循环用于评估模型的真实泛化能力。虽然计算成本高昂,但它提供了最无偏的性能估计。
与传统方法的对比:为何不再依赖“简单划分”?
在交叉验证普及之前,业界常用的方法是保持法(Hold-out Method),即简单地将数据分为训练集(如 70%)和测试集(如 30%)。这种方法虽然计算速度快,但存在显著缺陷,我们可以通过一个生动的类比来理解。
类比:学生的考试制度
- 保持法(Hold-out):就像学生只参加一次期末考试。如果这次考试的题目恰好都是学生复习过的(数据划分运气好),分数就会虚高;如果题目恰好覆盖了学生的盲区(数据划分运气差),分数就会极低。这种“一考定终身”的方式,无法真实反映学生的综合水平,且浪费了 30% 的数据仅用于一次测试,对于小数据集尤为奢侈。
- 交叉验证(Cross-Validation):相当于进行了 K 次模拟考。每次考试的侧重点不同(不同的验证集),学生必须在所有模拟考中都表现出色才能拿到高分。这不仅消除了题目难易度波动带来的运气成分,还让学生利用了 100% 的复习资料进行备考(每个样本都参与了训练)。
对比总结表:
| 特性 | 保持法 (Hold-out) | K 折交叉验证 (K-Fold CV) |
| :--- | :--- | :--- |
| 数据利用率 | 低(部分数据仅用于测试) | 极高(所有数据均参与训练和测试) |
| 评估稳定性 | 低(高度依赖随机划分) | 高(多次平均,消除方差) |
| 计算成本 | 低(训练 1 次) | 高(训练 K 次) |
| 适用场景 | 大数据集(>10 万条) | 中小数据集、模型调优阶段 |
| 过拟合风险 | 较高(易受特定测试集影响) | 较低(能更敏锐地发现过拟合) |
随着算力成本的降低和数据价值的提升,除非面对海量数据(此时单次划分的统计代表性已足够),否则交叉验证已成为机器学习工作流中的标准配置。
核心概念:构建完整的认知图谱
深入理解交叉验证,需要厘清一系列相关术语及其相互关系。这些概念构成了评估机器学习模型性能的基石。
关键术语解释
1. 泛化能力(Generalization Ability):
这是交叉验证旨在衡量的终极目标。它指模型在面对从未见过的新数据时,依然能保持良好预测性能的能力。交叉验证的得分越高,通常意味着模型的泛化能力越强。
2. 过拟合(Overfitting):
模型在训练集上表现完美,但在验证集上表现糟糕的现象。这就像学生死记硬背了课本例题,却不会做变式题。交叉验证是检测过拟合的最有效手段之一:如果训练集误差很低而交叉验证误差很高,就是典型的过拟合信号。
3. 偏差 - 方差权衡(Bias-Variance Tradeoff):
这是机器学习的核心困境。偏差(Bias)指模型预测值与真实值的差异(欠拟合),方差(Variance)指模型对训练数据微小变化的敏感程度(过拟合)。
- K 值的选择直接影响这一权衡。K 值较小(如 K=2),训练数据少,偏差大,方差小;K 值较大(如 K=N,即留一法),训练数据多,偏差小,但方差大(因为各折间相关性高)。通常 K=5 或 10 是经验上的最佳平衡点。
4. 留一法(Leave-One-Out Cross-Validation, LOOCV):
这是 K 折交叉验证的特例,其中 K 等于样本总数 N。每次只留一个样本作为验证集,其余 N-1 个作为训练集。
- *优点*:几乎无偏差,充分利用数据。
- *缺点*:计算量极大(需训练 N 次),且由于训练集高度相似,评估结果的方差可能很大。适用于极小样本数据集。
5. 时间序列交叉验证(Time Series Cross-Validation):
传统随机分割不适用于时间序列数据(如股票价格、天气预测),因为这会破坏时间依赖性并导致“未来数据泄露”。时间序列 CV 采用滚动窗口(Rolling Window)或扩展窗口(Expanding Window)策略,确保训练集的时间点永远早于验证集,严格遵循因果律。
概念之间的关系图谱
我们可以将这些概念想象成一个生态系统:
- 中心目标:泛化能力。
- 主要威胁:过拟合与欠拟合。
- 防御武器:交叉验证。
- 战术调整:通过调整K 值来平衡偏差与方差。
- 特殊战场:面对时间序列或类别不平衡数据时,需切换为时间序列 CV或分层 K 折。
- 最终产出:基于交叉验证得出的鲁棒性(Robustness)模型评估报告。
常见误解澄清
误解一:“交叉验证可以用来提高模型的准确率。”
- 真相:交叉验证本身不训练模型,也不直接提高模型性能。它是一个评估工具,用来告诉你当前的模型配置好不好。当然,通过它筛选出的最佳超参数间接提升了最终模型的质量,但 CV 过程只是“考官”,不是“教练”。
误解二:"K 值越大越好,100 折肯定比 5 折准。”
- 真相:不一定。随着 K 增大,计算成本线性增加。更重要的是,当 K 过大时,各折之间的训练集重叠度极高,导致评估结果的相关性增强,反而可能增加评估结果的方差。对于大多数应用,5 折或 10 折已在精度和效率间取得了最佳平衡。
误解三:“做了交叉验证就不需要独立的测试集了。”
- 真相:这是一个危险的误区。交叉验证主要用于模型选择和调参。一旦确定了最终模型架构和参数,必须在完全未参与过任何交叉验证过程的独立测试集(Hold-out Test Set)上进行最后一次“盲测”,以获取对上线后真实性能的无偏估计。如果在调参过程中反复使用测试集,测试集就变相成了验证集,导致评估失效。
实际应用:从理论到 2026 年的前沿实践
交叉验证不仅是教科书上的理论,更是工业界和科研界的实战利器。随着 AI 技术的发展,其应用场景和形式也在不断进化。
典型应用场景
1. 医疗诊断与药物发现:
在医疗领域,数据往往稀缺且珍贵(如罕见病影像数据)。研究人员利用留一法(LOOCV)或分层 K 折,在有限的病例数据上训练癌症检测模型。任何一点过拟合都可能导致误诊,因此严格的交叉验证是论文发表和临床审批的硬性要求。
2. 金融风控与反欺诈:
银行在构建信用评分卡或反欺诈模型时,面临严重的类别不平衡问题(欺诈案例极少)。此时,分层交叉验证确保每一折中都包含相同比例的欺诈样本,防止模型简单地预测“所有人都是诚实的”来获得高准确率。此外,针对交易数据的时间特性,时间序列交叉验证被广泛用于回测策略的有效性。
3. 自动驾驶感知系统:
在训练识别行人、车辆的深度学习模型时,数据采集环境多样(雨天、夜间、逆光)。通过分组交叉验证(Group K-Fold),可以将同一场景或同一辆车采集的数据归为一组,确保训练集和验证集在场景上是隔离的,从而评估模型在新环境下的适应能力。
代表性产品与项目案例
- Scikit-learn (Python):
作为全球最流行的机器学习库,Scikit-learn 内置了极其丰富的交叉验证模块(`sklearn.model_selection`)。从基础的 `cross_val_score` 到复杂的 `GridSearchCV`(网格搜索结合 CV),它降低了技术门槛,让初学者也能一键实现专业的模型评估。它是无数数据科学项目的基石。
- Kaggle 竞赛平台:
在全球顶级数据科学竞赛中,高分选手的核心秘诀往往不在于模型有多复杂,而在于本地交叉验证方案(Local CV Scheme)设计得有多精妙。选手们会精心设计符合比赛数据分布的 CV 策略(如基于地理位置的分层、基于时间的切分),以确保本地分数的提升能真实反映公共排行榜(Public Leaderboard)的提升,防止“过拟合排行榜”。
- AutoML 平台(如 Google Vertex AI, H2O.ai):
2024-2026 年间,自动化机器学习(AutoML)蓬勃发展。这些平台将交叉验证封装在底层自动化流程中。用户只需上传数据,系统自动执行数十种模型的海量交叉验证实验,自动选择最优配置。这使得非专家用户也能享受到严谨的模型评估红利。
2026 年应用进展与趋势展望
站在 2026 年的视角回望,交叉验证技术在应对新一代 AI 挑战时呈现出新的演进方向:
1. 大模型时代的轻量化验证:
随着千亿参数大语言模型(LLM)的普及,传统的 K 折微调(Fine-tuning)成本过高。2026 年的趋势是发展基于代理的交叉验证(Proxy-based CV)和少样本评估协议。研究者不再对整个大模型进行 K 次全量训练,而是利用低秩适配器(LoRA)等高效微调技术,结合小规模的代表性验证集,快速估算模型在特定下游任务的表现。
2. 联邦学习中的隐私保护交叉验证:
在数据不出域的联邦学习(Federated Learning)场景下,传统集中式交叉验证无法实施。2026 年,分布式交叉验证协议已成标配。各节点在本地进行部分验证,通过安全多方计算(MPC)聚合结果,既完成了模型评估,又严格保障了用户隐私数据的机密性。
3. 生成式 AI 的质量评估新范式:
对于生成式模型(如文生图、视频生成),传统的准确率指标失效。新型的语义一致性交叉验证应运而生。它将生成的内容再次输入判别模型,或通过多轮次的内容重构(Cycle-Consistency),在不同子集上验证生成内容的稳定性和语义保真度,成为评估 AIGC 质量的新标准。
使用门槛和条件
尽管交叉验证功能强大,但要正确使用并非零门槛:
- 数据独立性假设:标准 CV 假设样本间相互独立。若数据存在强相关性(如来自同一用户的多次点击),需使用Group K-Fold。
- 计算资源:对于深度神经网络,K 折意味着训练时间乘以 K。企业需具备相应的 GPU 集群或云算力支持,或采用近似验证策略。
- 代码实现能力:虽然库函数封装良好,但设计合理的分割策略(特别是处理时间序列、空间数据或不平衡数据时)仍需深厚的领域知识和编程经验。
延伸阅读:通往专家之路
掌握交叉验证只是迈入严谨机器学习世界的第一步。为了构建更完备的知识体系,建议读者沿着以下路径继续探索。
相关概念推荐
- 自助法(Bootstrap):另一种重采样技术,通过有放回抽样构建数据集,常用于估计统计量的置信区间,与交叉验证互为补充。
- 贝叶斯优化(Bayesian Optimization):比网格搜索更高效的超参数调优方法,常与交叉验证结合使用,以更少的迭代次数找到最优解。
- 学习曲线(Learning Curves):绘制训练集和验证集误差随数据量变化的曲线,是诊断模型是处于高偏差还是高方差状态的可视化工具。
- 数据泄露(Data Leakage):深入了解导致模型评估虚高的各种隐蔽原因,是避免“纸上谈兵”的关键。
进阶学习路径
1. 基础阶段:熟练掌握 Scikit-learn 中的 `train_test_split`, `KFold`, `StratifiedKFold`, `cross_val_score` 等 API 的使用。
2. 进阶阶段:深入研究嵌套交叉验证的代码实现,理解其在模型选择中的必要性;尝试处理时间序列和不平衡数据的特殊分割策略。
3. 高阶阶段:阅读关于分布外泛化(Out-of-Distribution Generalization)的文献,探索在非平稳分布下如何设计更鲁棒的验证框架;研究大模型时代的高效评估协议。
推荐资源和文献
- 经典教材:
- 《The Elements of Statistical Learning》(统计学习基础)- Hastie et al. 第 7 章详细论述了模型评估与选择的理论基础,是必读经典。
- 《Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow》- Aurélien Géron. 提供了大量实用的代码示例,特别适合工程实践。
- 权威论文:
- *"A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection"* (Ron Kohavi, 1995). 这篇论文实证比较了多种评估方法,奠定了 10 折交叉验证的行业标准地位。
- 近年关于 *"Evaluation Metrics for Generative Models"* 的相关综述,了解生成式 AI 时代的验证新动向。
- 在线资源:
- Scikit-learn 官方文档:其 "Model Selection" 章节是世界上最清晰的交叉验证教程之一。
- Kaggle Learn:提供交互式的微课程,涵盖从基础划分到高级验证策略的实战演练。
- Coursera / DeepLearning.AI:吴恩达教授的机器学习系列课程,对偏差 - 方差权衡及验证方法有深入浅出的讲解。
交叉验证不仅是一项技术,更是一种科学思维方式的体现:它教导我们对数据保持敬畏,对结论保持审慎,通过反复的证伪与验证,逼近真理。在人工智能飞速发展的 2026 年,无论模型架构如何演变,这种严谨的评估精神将永远是可靠 AI 系统的基石。