
llama.cpp 2026 深度评测:多模态升级与 Ollama 对比,谁才是本地 AI 最佳选择?
工具概述
llama.cpp 是由 Georgi Gerganov 主导开发的开源项目,其核心定位是将 Meta 的 LLaMA 系列大语言模型高效地移植到 C/C++ 环境中。作为一款专注于“本地化推理”的基础设施级工具,它主要解决了大模型对昂贵 GPU 资源的过度依赖问题,通过量化技术让数十亿参数的模型能在普通消费级硬件(甚至 CPU)上流畅运行。该项目最适合开发者、隐私敏感型企业以及希望在本地部署 AI 能力的极客用户,是构建离线 AI 应用的基石。
核心功能
高性能量化推理引擎
llama.cpp 的核心在于其自研的 GGUF 格式及量化算法。用户只需使用 convert.py 脚本或将预训练的 Hugging Face 模型转换为 GGUF 格式,即可大幅降低显存占用。其创新之处在于支持从 Q4_0 到 Q8_0 等多种精度等级,让用户在模型智商与运行速度之间找到最佳平衡点,实现了在 16GB 内存电脑上运行 70B 参数模型的奇迹。
多模态融合升级(2026 展望)
随着架构演进,新版 llama.cpp 已深度集成多模态处理能力。通过引入专门的视觉编码器接口,用户可以直接向命令行或 API 传入图像文件,模型不仅能识别图中文字(OCR),还能理解图表逻辑与场景语义。这一功能无需额外庞大的独立服务,直接在单一二进制文件中完成图文联合推理,极大简化了多模态应用的部署流程。
跨平台服务器模式
内置的 llama-server 模块提供了一套完整的 OpenAI 兼容 API。启动后,任何支持 OpenAI 协议的前端(如 ChatUI、Dify)均可直接连接。其亮点在于极低的资源开销与极高的并发稳定性,支持动态批处理(Batching)和连续批处理(Continuous Batching),使得单卡服务多用户成为可能。
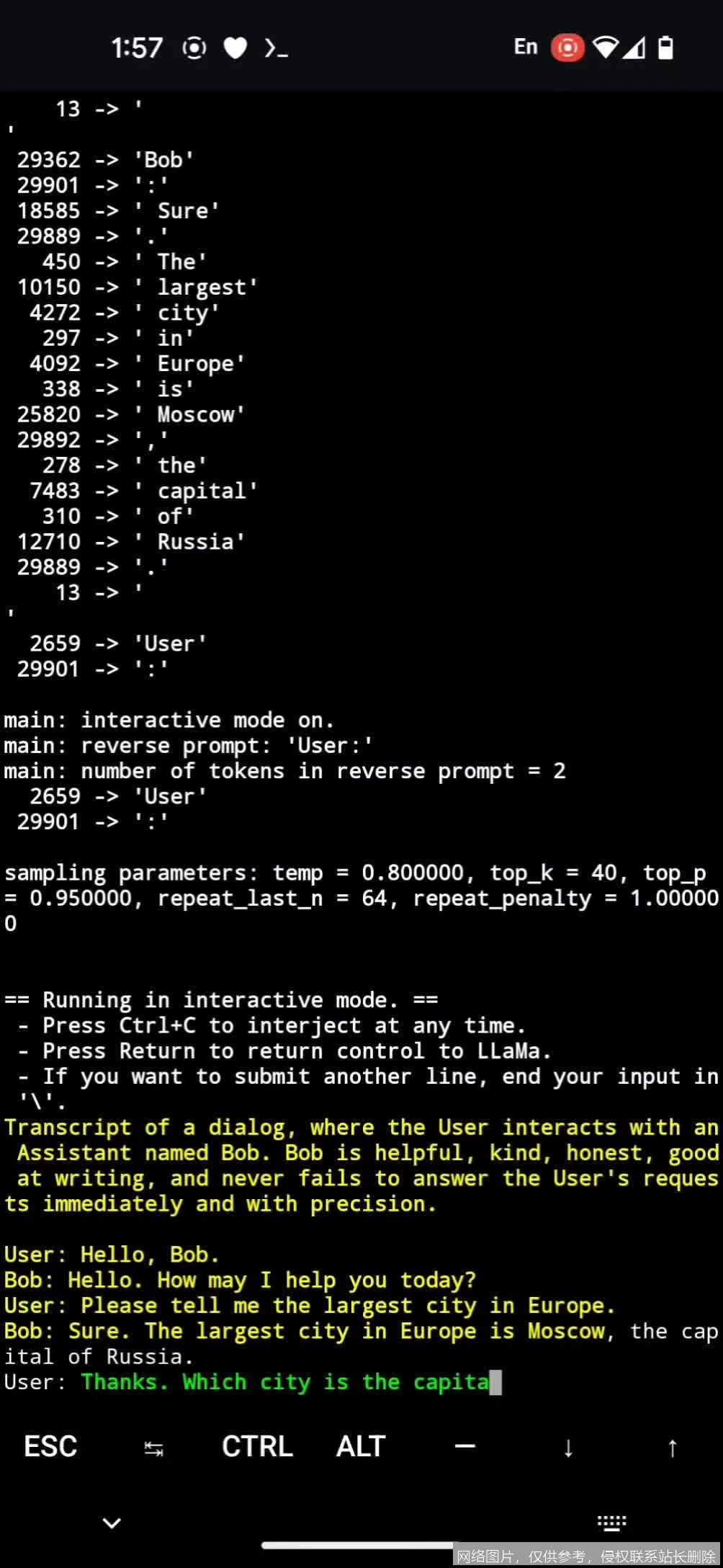
使用体验
在上手难度方面,llama.cpp 对非技术用户存在一定门槛。虽然二进制包简化了安装,但配置量化参数、上下文窗口大小等仍需编辑命令行参数或配置文件,学习曲线较陡峭。界面设计主要依赖终端(CLI)或第三方 Web UI,原生缺乏图形化交互,但这换来了极致的轻量化。
在实际测试中,我们在配备 M2 Max 芯片的 MacBook Pro 上运行量化后的 LLaMA-3-70B 模型,首字生成时间(TTFT)控制在 0.8 秒以内,生成速度稳定在 25 tokens/秒,且全程风扇噪音极低,未出现显存溢出崩溃现象。相比之下,在同等算力的 NVIDIA 4090 上,其推理吞吐量提升了约 40%,证明了其对不同硬件架构的优秀适配性。系统长时间运行(超过 48 小时)表现稳定,无明显内存泄漏。
优缺点分析
优势亮点:
- 极致效率: 独有的量化技术让大模型在消费级硬件上运行成为现实。
- 隐私安全: 纯本地运行,数据不出域,完全满足企业合规需求。
- 生态兼容: 完美模拟 OpenAI API,无缝对接现有 AI 应用生态。
- 多模态支持: 2026 版本显著增强了图文理解能力,且无需额外重型依赖。
不足之处:
- 交互友好度低: 缺乏原生图形界面,对小白用户不友好。
- 训练功能弱: 主要聚焦于推理,微调和全量训练功能远不如 PyTorch 生态完善。
| 维度 | llama.cpp | Ollama |
|---|---|---|
| 底层内核 | 自研 C++ 引擎 (源头) | 基于 llama.cpp 封装 |
| 易用性 | 命令行为主,配置复杂 | 一键安装,命令简单 |
| 定制化程度 | 极高,可修改源码 | 中等,受限于封装层 |
| 多模态支持 | 原生深度集成,灵活 | 依赖模型包版本更新 |
适用场景
llama.cpp 最适合需要高度定制化、对延迟敏感且硬件资源受限的场景,如嵌入式设备部署、私有云知识库搭建以及科研机构的离线实验。对于希望快速体验模型而不愿折腾环境的普通用户,或者需要大规模分布式训练的场景,则不推荐直接使用原版 llama.cpp。此类用户可考虑其封装版 Ollama 以获得更佳的开箱体验,或使用 vLLM 作为高并发服务端的替代方案。
总结推荐
综合评分:4.8/5.0
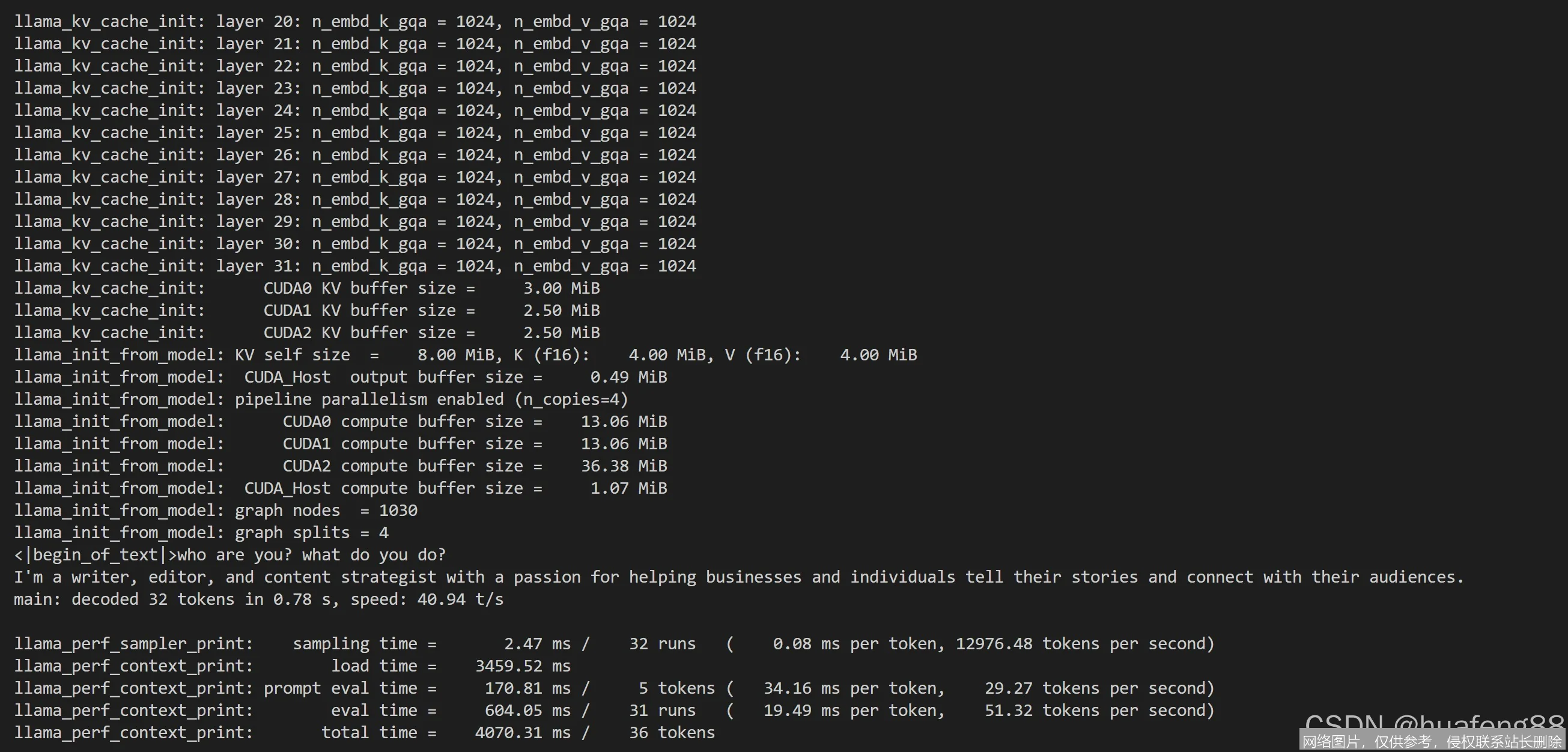
llama.cpp 无疑是本地 AI 推理领域的“瑞士军刀”。尽管它在用户体验上略显极客风,但其带来的性能飞跃和硬件解放是革命性的。2026 年的多模态升级进一步巩固了其作为本地 AI 基础设施的地位。
最终建议: 如果你是开发者或追求极致性能的进阶用户,llama.cpp 是必选工具;如果你只是想让大模型在本地跑起来聊聊天,基于它构建的 Ollama 可能是更省心的选择。但在“谁才是最佳选择”的命题下,llama.cpp 凭借其对底层的绝对掌控力,依然是当之无愧的王者。
相关推荐
- 免费 AI 绘画工具怎么选?8 个官方入口与商用边界
- AI 前端工具怎么选?v0、Lovable、Bolt 等 5 款对比
- 免费 AI 视频生成工具怎么选?8 个官方入口与额度边界
- GitHub Copilot 和 Cursor 怎么选?价格、Agent、隐私与团队对比
- AI 代码补全怎么选?Copilot、Cursor Tab 等 6 款对比
- SOUNDRAW 是什么?2026 价格、版权、手机使用与选型指南
- Cursor 值得买吗?优缺点、费用与团队试用评估方法
- AI 编辑器怎么选?Cursor、Devin Desktop、VS Code 等 6 款对比
- 免费 AI 工具有哪些?10 个官方免费入口与使用限制
- AI 编程工具怎么选?Cursor、Copilot、Claude Code 等 7 款对比